Blog
Automation
Automation ist für viele Unternehmungen und Organisationen der Schlüssel zu mehr Effizienz.

Aufgrund der agilen Vorgehensweisen in vielen IT-Bereichen und um den dadurch resultierenden kürzeren Bereitstellungszeiten von IT-Infrastruktur nachzukommen, denken viele IT-Organisationen darüber nach, was mit vertretbarem Aufwand automatisiert werden könnte, um die wachsenden Anforderungen seitens des Business zu erfüllen.
Neben der Agilität sind es auch die Kosten und nicht zuletzt die geforderte Qualität, welche der Automatisierung Vorschub leisten. Ist ein Ablauf einmal automatisiert, dann können auch anders qualifizierte IT-Mitarbeiter, oder im besten Falle der Besteller eines Services selbst, diesen Schritt durchführen, was sich schlussendlich auch positiv auf die Kosten auswirkt.
Bedingungen
Um einen Vorgang automatisieren zu können, muss dieser zwingend standardisiert sein, also mit möglichst wenigen Ausnahmen immer gleich ablaufen. Zudem muss dieser Vorgang häufig angefordert und durchgeführt werden, um den Aufwand einer Automatisierung zu rechtfertigen.
Eine Automatisierung erfordert zudem, dass die IT-Infrastruktur in den Bereichen Compute, Storage und Netzwerk virtualisiert ist. Wenn jedes Mal, wenn eine zusätzliche Instanz eines Service im Datacenter aufgeschaltet werden soll, Hardware angeschafft und installiert werden muss, kann nicht automatisiert werden.
Art der Automation
Es wird zwischen der vertikalen und der horizontalen Automatisierung unterschieden. Diese Grafik zeigt den Unterschied.
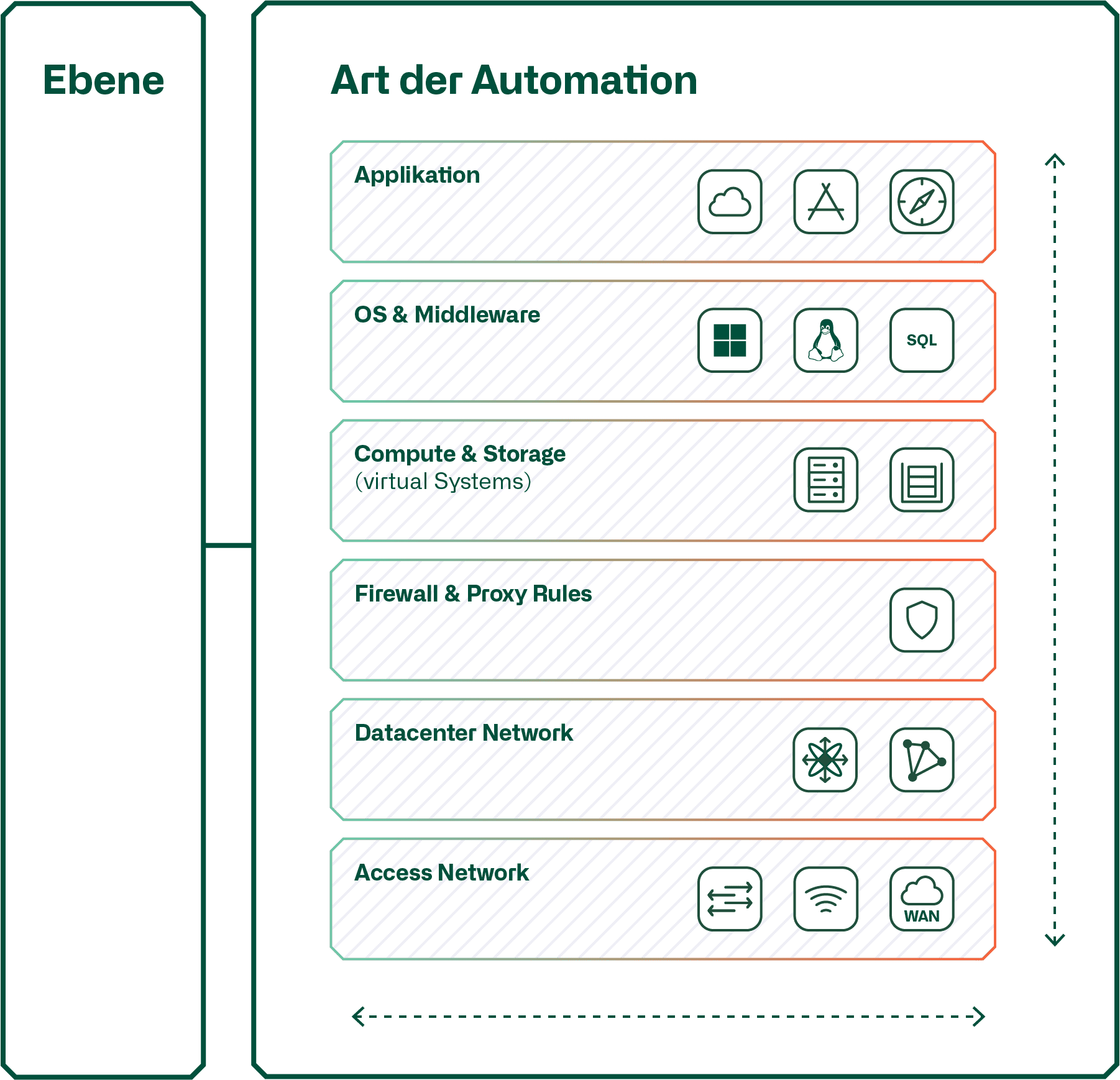
Bei der horizontalen Automation werden die Vorgänge beschränkt auf die jeweilige Ebene automatisiert. Hier als Beispiel das Datacenter Netzwerk, welches mit einer «out of the Box» SDN-Lösung eines Netzwerkherstellers automatisiert wird. Oder die Ebene «Firewall & Proxy Rules» wird mit einem Firewall-Policy-Management automatisiert. Das Gleiche gilt für die Ebene «Compute & Storage», welche mit den Automatisierungstools der Lieferenten der Virtualisierung von Compute oder Storage automatisiert werden.
Erst wenn die einzelnen Ebenen ausreichend automatisiert sind, kann eine vertikale Automatisierung realisiert werden, um Instanzen eines multilayer Service, also eines Service, welcher aus Services verschiedener Ebenen besteht, automatisiert zu provisionieren. Oftmals spricht man im Falle der vertikalen Automatisierung auch von Orchestrierung. Eine vertikale Automatisierung bedingt, dass die zur Automatisierung einer Ebene eingesetzten Produkte ein «Northbound API» aufweisen. Dieses wird vom Orchestrator der vertikalen Automatisierung verwendet, um Instanzen in der entsprechenden Ebene zu provisionieren. Zum Beispiel, um auf der Ebene «Datacenter Network» einen virtuellen Router mit den dazugehörenden VLANs zu konfigurieren, mit welchen der Orchestrator in einem weiteren Schritt die VMs via dem Compute Automatiserungstool verbindet.
Architektur Automatisierungstools
Die Automatisierungstools einer Ebene weisen alle in etwa dieselbe Architektur aus. Diese ist in der folgenden Grafik dargestellt.
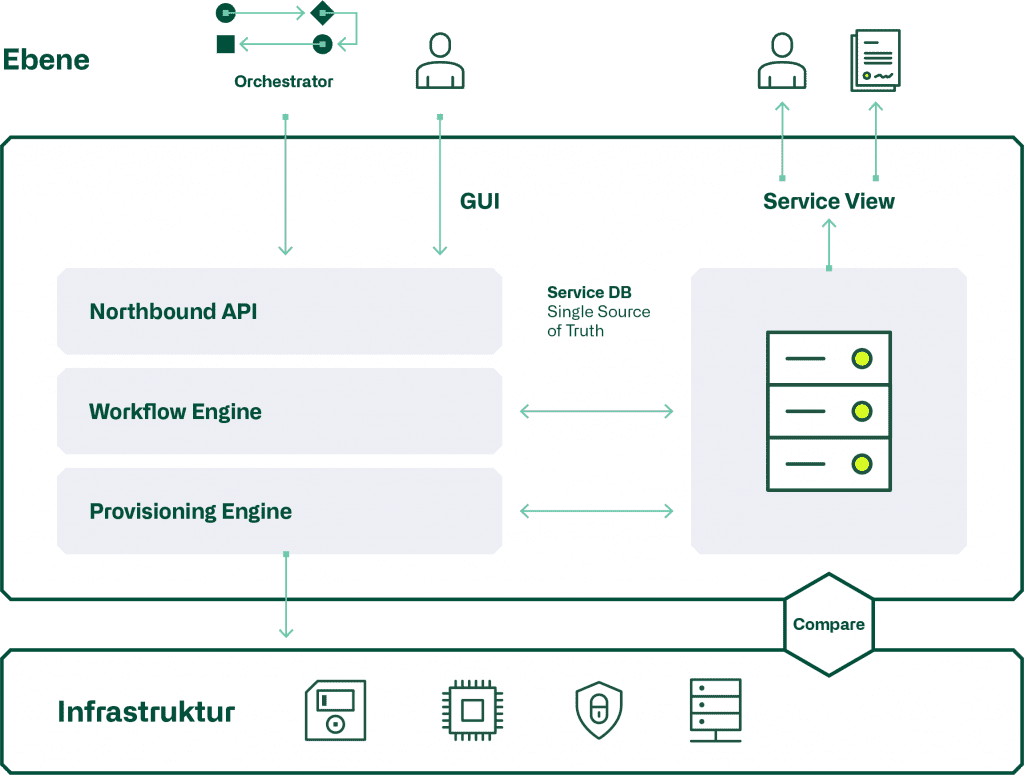
Beginnen wir mit dem «Northbound API», welches verwendet wird um die Services einer Ebene zu konfigurieren. Dies geschieht entweder mittels dem GUI durch eine Person, oder direkt durch den Orchestrator der vertikalen Automation. Entscheidend ist hier, dass auch das GUI das «Northbound API» verwendet, da so sichergestellt ist, dass alle GUI Funktionen auch den Orchestrator zur Verfügung stehen.
Die «Workflow Engine» führt die verschiedenen Schritte durch, welche den Service ausmachen. Anschliessend erstellt die «Provisioning Engine» die zur Konfiguration notwendigen «Snipplets», welche dann via Rest-API, Netconf oder CLI auf die Komponenten der Infrastruktur provisioniert werden. Die Struktur und die Parameter eines Service werden in der Service DB festgehalten, welche immer den «Single Source of Truth» darstellt.
In einer Model-Driven Automatisierung werden die Konfigurationen der Infrastrukturkomponenten periodisch. mit der Service DB abgeglichen. Hier stellt sich die Frage, wie mit den Abweichungen umgegangen wird. Oftmals wird nur ein Reporting erstellt und die Differenzen müssen manuell bereinigt werden, da ein direktes Reprovisioning aus der Service DB einen Unterbruch des betroffenen Service zur Folge haben könnte.
Zudem kann aus der Service DB mittels dem «Service Viewer» die Service-Struktur und die -Parameter in der Form eines Service-Tree direkt online, oder als Report dargestellt werden. Dies ist ein wichtiges Feedbackinstrument, um die korrekte Funktion der Workflow- und der Provisionig-Engine zu überprüfen.