Containerisierung einer Applikation
Mittels Containerisierung lässt sich Programmcode bündeln, verteilt in isolierten Umgebungen ausführen, patchen und skalieren. Die Entwicklung und Bereitstellung von Applikationen wird dabei vereinfacht und modular gegliedert. Trotz all ihrer vielen Vorteile macht eine Containerisierung jedoch nicht immer Sinn, denn der Weg zur optimalen Container-Infrastruktur kann sich ohne Plan als lang und steinig erweisen.
In diesem Blog stellen wir vor, welche Schritte notwendig sind, um eine Applikation zu containerisieren, welche Vorteile dies bietet und zu welchem Zeitpunkt eine Containerisierung in Erwägung gezogen werden kann. Zusätzlich zeigen wir wichtige Aspekte auf, die im Vorgehen der Containerisierung einer Applikation beachtet werden müssen, um die Implementierung und den Betrieb von Containern erfolgreich zu gestalten.
Konzept Containerisierung
Die Containerisierung ermöglicht die Zerlegung von Anwendungen in «Container». Dadurch kann Programmcode innerhalb eines Containers mitsamt seinen Abhängigkeiten (Bibliotheken, Frameworks, sonstige Dateien) als eigenes Softwarepaket gebündelt und als Prozess ausgeführt werden. Die Bündelung eines solchen Softwarepakets erfolgt in Form von Images, welche z.B. über Docker bereitgestellt werden.
Ein weiteres Merkmal von Containern ist deren Einsatz als schlanke Alternative zu herkömmlichen virtuellen Maschinen, weil sie für den Betrieb kein eigenes Betriebssystem benötigen. Sie verwenden für das Ausführen von Prozessen den Betriebssystem-Kernel ihres Host-Systems. Sämtliche Container innerhalb einer Container-Infrastruktur teilen sich dabei den gleichen Kernel eines zentralen Host-Systems, haben aber keinen Zugriff auf ihre Nachbar-Container untereinander.
Durch den geteilten Betriebssystem-Kernel ist sichergestellt, dass eine containerisierte Anwendung jeweils im gleichen Kontext plattformunabhängig ausgeführt werden kann.
Warum Containerisieren?
Es stellt sich nun die Frage, wieso Software-Entwicklungsfirmen überhaupt ihre Applikationen in ihre Einzelteile zerlegen sollen. Der Nutzen muss dabei den Aufwand decken, um den Weg zur Containerisierung rechtfertigen zu können.
Die Containerisierung einer Applikation bietet folgende Vorteile gegenüber dem klassischen, meist monolithischen Ansatz, mit welchem die Applikation in einer oder mehreren virtuellen Maschinen betrieben wird:
- Reduzierte Betriebskosten
Durch das Weglassen eines eigenen Betriebssystems lassen sich Speicherplatz, Rechenleistung und Ressourcen einsparen. Ein Container-Image benötigt lediglich genug Leistung, um die Prozesse innerhalb seines Softwarepakets auszuführen. - Skalierbarkeit
Container lassen sich innerhalb kurzer Zeit starten und stoppen. Sofern für eine Applikation mehr Rechenleistung benötigt wird, können innert kürzester Zeit neue Container durch die Bereitstellung eines Images aufgesetzt werden. Dies ermöglicht einen hohen Grad an Skalierbarkeit. - Portabilität
Durch die Natur der Modularität eines Containers lassen sich diese vereinzelt in neue Infrastrukturen bereitstellen und migrieren. Dies ist z.B. im Fall einer bevorstehenden Cloud-Journey praktisch, in welche Teile einer containerisierten Applikation aus einer On-Premises Landschaft in eine Cloud Umgebung migriert werden. Hierbei soll ebenso erwähnt sein, dass die meisten SaaS-Lösungen auf containerisierten Backend-Softwaremodulen aufbauen. - Performance
Bei herkömmlichen Ansätzen in der Virtualisierung geht immer ein gewisser Teil der Performance eines Systems für den Betrieb des Betriebssystems verloren.
Ein Container ist dazu da, Prozesse auszuführen, für welche er erstellt worden ist. Aufgrund dieser Isolierung kann die gesamte Rechenleistung innerhalb eines Containers auf die Ausführung der Prozesse gelegt werden. - Konsistenz
Angesichts der Tatsache, dass alle Container denselben Betriebssystem-Kernel ihres Host-Systems verwenden, bildet der Kernel zugleich auch dieselbe Basis der Funktionalität und Betriebsumgebung der Container. Somit werden die Entwicklung und Bereitstellung einer Applikation wesentlich vereinfacht, weil deren containerisierten Module in allen Umgebungen gleich funktionieren. - Optimiert für moderne DevOps-Ansätze
Mittels DevOps wird die Prämisse geschaffen, eine kontinuierliche und sofortige Integration von Code in bestehende Umgebungen garantieren zu können. Anhand von Orchestrierungstools wie Kubernetes können DevOps Teams innerhalb kurzer Zeit einzelne Container oder gesamte containerisierte Anwendungen bereitstellen, versionieren und rollbacken. Der gesamte Lebenszyklus einer Applikation kann deshalb mithilfe von DevOps gesteuert und verwaltet werden.
Von Legacy-Applikation zur Container-Infrastruktur
Durch die vielen direkten Vorteile der Containerisierung und den fortlaufenden Drang von Unternehmen zur Modernisierung ihrer Legacy-Systeme, welcher durch Trends wie z.B. Cloud Computing verstärkt wird, stellt sich nun die Frage:
Wieso fangen nicht alle Unternehmen an, ihre Applikationen als Container zu betreiben? Die Beantwortung dieser Frage bildet zugleich den ersten Schritt des Wegs zur Containerisierung einer Applikation.

Analyse- und Planungsphase
Vor der Erwägung einer Containerisierung muss im Voraus Verständnis über die betroffene Applikation geschaffen werden. «Verständnis schaffen» heisst, sich bewusst werden, aus welchen Komponenten die zu migrierende Applikation besteht, wie ihre Architektur aussieht und wie die Komplexität einer Zerlegung eingeschätzt wird. Es macht beispielsweise wenig Sinn, eine hochkomplexe Applikation zu containerisieren, die aus zahlreichen Komponenten inkl. Abhängigkeiten besteht. Ziel einer Containerisierung ist es, den Betrieb und die Verwaltung einer Applikation zu vereinfachen, nicht zu verschlimmbessern.
Um solche Fälle zu vermeiden, ist es wichtig, folgende Fragen zu klären:
- Ist es möglich, die Applikation in logische, funktionale Bereiche zu gliedern?
- Lassen sich diese Bereiche isoliert in einem Container ausführen?
- Aus wie vielen Containern würde die Applikation grob geschätzt bestehen?
Neben den Managementaspekten, welche es bei einer Evaluation einer Containerisierung zu berücksichtigen gibt, gibt es auch Sicherheitsaspekte, auf die Acht gegeben werden muss. Während der geteilte Kernel im Vergleich zu herkömmlichen Betriebssystem-VMs für den Betrieb und die Performance sehr vorteilhaft ist, bildet dieser Infrastruktur-Umstand auch ein erhöhtes Sicherheitsrisiko im Falle einer Cyber-Attacke. So bildet beispielsweise die Angriffsmöglichkeit auf den Kernel des Host-Systems eine Angriffsfläche auf alle Container innerhalb einer containerisierten Applikation desselben Container-Host-Systems.
In der Analysephase ist es zwingend notwendig, solche Konsequenzen und solche Risiken und allfällige Konsequenzen im Voraus gründlich zu analysieren, um entsprechende Sicherheitsmassnahmen treffen zu können.
Auswahl Technologie
Nach einer positiven Evaluation einer Applikation hinsichtlich Containerisierung, steht die Auswahl einer passenden Container-Technologie an. Vor der Auswahl der Technologie muss ebenfalls die Umgebung der Infrastruktur definiert werden: On-Premises oder Cloud?
Die Auswahl zwischen den beiden Optionen hängt von den Anforderungen an die zu containerisierende Applikation ab, welche sich in der Analysephase ergeben. Wichtige Überlegungen hierbei sind zum Beispiel die Anforderungen an die Skalierbarkeit, Sicherheit, Verfügbarkeit und Kosten. Entsprechend wird eine Evaluation der Vor- und Nachteile jeder Umgebung vorausgesetzt, um eine Entscheidung treffen zu können.
Als Container-Technologie werden wir für diesen Blog den Implementierungsgrundsatz wählen, der Docker heisst. Docker ist besonders für seine Einfachheit und Effizienz bekannt und hat sich als Industriestandard für Containerisierung etabliert.
Abhängigkeiten erkennen
Das Identifizieren von Abhängigkeiten der Applikation ist der nächste Schritt in der Analysephase und ist die Voraussetzung für die Definition einer Zielarchitektur. Abhängigkeiten sind Elemente wie externe Bibliotheken, benutzerdefinierte Frameworks oder Konfigurationsdateien, welche Teil des Container-Images bilden. Externe Dienste wie Datenbanken und API-Schnittstellen werden meistens ausserhalb des Containers betrieben. Die Unterscheidung zwischen externen Komponenten und Teilen des Container-Images ist notwendig, um eine containerbasierte Applikation richtig zu konfigurieren.
Daten innerhalb eines Container-Images sind im Vergleich zu bezogenen Daten aus externen Datenbanken und Schnittstellen meistens flüchtig und nicht persistent. Die aufgezählten Abhängigkeiten müssen während der Segmentierung der Applikation in einzelne Services berücksichtigt werden.
Zielarchitektur definieren
Basierend auf der ausgewählten Technologie und den erkannten Abhängigkeiten wird die Zielarchitektur der Container-Infrastruktur definiert. An dieser Stelle möchten wir besonders auf die Wahl des Standorts der Applikationsdaten verweisen. Es ist von zentraler Bedeutung, in der Zielarchitektur festzulegen, welche Art von Daten nach einer möglichen Aufteilung der Applikation wo abgespeichert werden. Eine (containerisierte) Applikation in der Cloud verfügt über andere Anforderungen an die Sicherheit als eine Applikation, welche sich On-Premises befindet. Ein Container, welcher streng vertrauliche Daten innerhalb der Applikation verarbeitet, stellt nicht dieselben Anforderungen an die Sicherheit, wie ein Container, welcher rein das Benutzerinterface eines Webportals hostet.
Priorisierung der Services
Die Resultate aus der Analysephase und die definierte Zielarchitektur ermöglichen eine verlässliche Priorisierung, welche die Reihenfolge der Migration bestehender Services in die neue Container-Infrastruktur vorgibt. Die Priorisierungskriterien stellen sich aus unterschiedlichen Faktoren zusammen. Diese Faktoren müssen entsprechend gewichtet werden. Die Gewichtung orientiert sich dabei anhand der definierten Anforderungen sowie den Eigenschaften der Applikation.
- Relevanz des Services in Bezug auf Geschäftsprozesse
- Technische Komplexität des Serviceaufbaus
- Höhe des geschätzten Aufwands für die Containerisierung
- Grad der Sicherheit
- Etc.
Vorbereiten und Implementieren
Nach Abschluss der Arbeiten in der Analyse- und Planungsphase erfolgt der Übergang zu einer containerbasierten Architektur. Dieser beginnt mit der Installation und dem Aufsetzen der Plattform, definiert gemäss Zielarchitektur. Im Kern dieser Phase steht die Erstellung und Konfiguration der Docker-Images für die einzelnen Container sowie anderen Artefakten, welche die Grundlage für die containerisierte Anwendung bilden.
Containerisierungsprozess
Der Prozess hinter der Erstellung der Container-Images hängt von der ausgewählten Technologie ab. Basierend auf Docker fängt dieser bei der Erstellung einer Datei zur Komposition des Docker-Aufbaus an. Man nennt diese Datei «Dockerfile». Ein «Dockerfile» ist eine textbasierte Konfigurationsdatei in YAML-Notation, welche alle Befehle in einer spezifischen Reihenfolge enthält, um ein Container-Image zu erstellen. Bei der Erstellung des Dockerfile ist es ebenfalls wichtig, dies mit Versionierungs-Tags zu versehen. Durch Versionierungs-Tags können Container-Images mit Informationen versehen werden, welche für Entwickler der Applikation helfen, zwischen Test- oder Produktiv-Images unterscheiden zu können.
Die Container-Images werden, wie in der vorherigen Phase definiert, gemäss den einzelnen Microservices aufgeteilt und gegliedert. Nachdem das Container-Image erfolgreich erstellt worden ist, kann es direkt innerhalb von Docker getestet werden. Nach einer erfolgreichen Testphase kann das Docker-Image entweder an einem speziell für die Zielarchitektur bestimmten Speicherort oder in einer Container Registry gespeichert werden. Die Anzahl der benötigten Docker-Images und Container einer Applikation hängt von der definierten Zielarchitektur und deren Komponenten ab. Die fertigen Container-Images können anschliessend über eine Container Orchestration Plattform als Grundlage für lauffähige Container bereitgestellt werden.
Container Orchestrierung
Ein Container Orchestrierungstool ist ein System für die Verwaltung, das Deployment und den Betrieb von Containern. Mittels Container Orchestration können Container skaliert, organisiert und innerhalb kürzester Zeit auf ihre vorgesehenen Plattformen bereitgestellt werden. Container Orchestrierungstools ermöglichen ebenso das Tracking der Auslastung, der Rechenleistung und der Verfügbarkeit von Containern, weshalb sie auch für deren Monitoring eingesetzt werden. Eines der führenden Orchestrierungstools für Container ist Kubernetes. Kubernetes ermöglicht die Verwaltung von Clustern, die aus Nodes bestehen:

Die Nodes in Kubernetes können physische oder virtuelle Maschinen sein. Sie sind die Arbeitseinheiten, welche die Container ausführen, skalieren und überwachen. Ein Kubernetes-Cluster setzt sich zusammen aus mindestens einem Master-Node, der die Orchestrierung und Verwaltung des Clusters übernimmt, und mehreren Worker-Nodes, auf denen Applikation(en) in Containern laufen.
Die Nutzung von Nodes innerhalb von Kubernetes ermöglicht die Kontrolle über Ressourcen und bietet eine hohe Verfügbarkeit durch Replikation. Durch Features wie automatische Skalierung kann eine Applikation basierend auf ihrer Auslastung dynamisch skaliert werden, um Ressourceneffizienz und optimale Performance zu gewährleisten.
Es ist von zentraler Bedeutung, auf ein Orchestrierungstool beim Aufbau einer containerbasierten Infrastruktur zu setzen, um die Übersicht sämtlicher Container bei vorgesehenem Wachstum einer Applikationslandschaft beibehalten zu können und zu vereinfachen. Da es in der Natur von Orchestrierungstools liegt, etliche manuelle Prozesse bei der Container-Bereitstellung zu automatisieren, sind sie auch perfekt geeignet für die Implementation von modernen DevOps-Ansätzen durch CI/CD Pipelines.
Integration und Betrieb
Integration von CI/CD und Devops durch Orchestration
Der gesamte Containerisierungsprozess lässt sich mithilfe von Container Orchestrierung und CI/CD Pipelines im Tagesbetrieb automatisiert in neue oder bestehende DevOps-Praktiken integrieren. Dies vereinfacht nicht nur das Deployment, sondern auch die Wartung der containerisierten Applikation erheblich. Neue Builds eines Container-Images können durch vorkonfigurierte «Build-Pipelines» innerhalb von wenigen Minuten auf bestehende oder neue Container getestet und produktiv bereitgestellt werden.
Besonders für Verteilungsansätze wie das Blue-Green Deployment eignet sich eine containerisierte Applikation sehr gut, weil Container schnell, konsistent ohne Umbruch im Datenverkehr bereitgestellt werden können. Die Isolation und Sicherheit von Containern minimiert die Fehleranfälligkeit und ermöglicht einfache Rollbacks zu vorherigen Versionen beim Auftreten von Problemen. Darüber hinaus optimieren Container die Ressourcennutzung, was sich als besonders vorteilhaft im Parallelbetrieb von mehreren Versionen einer Anwendung erweist, wie es im Blue-Green Deployment der Fall ist.
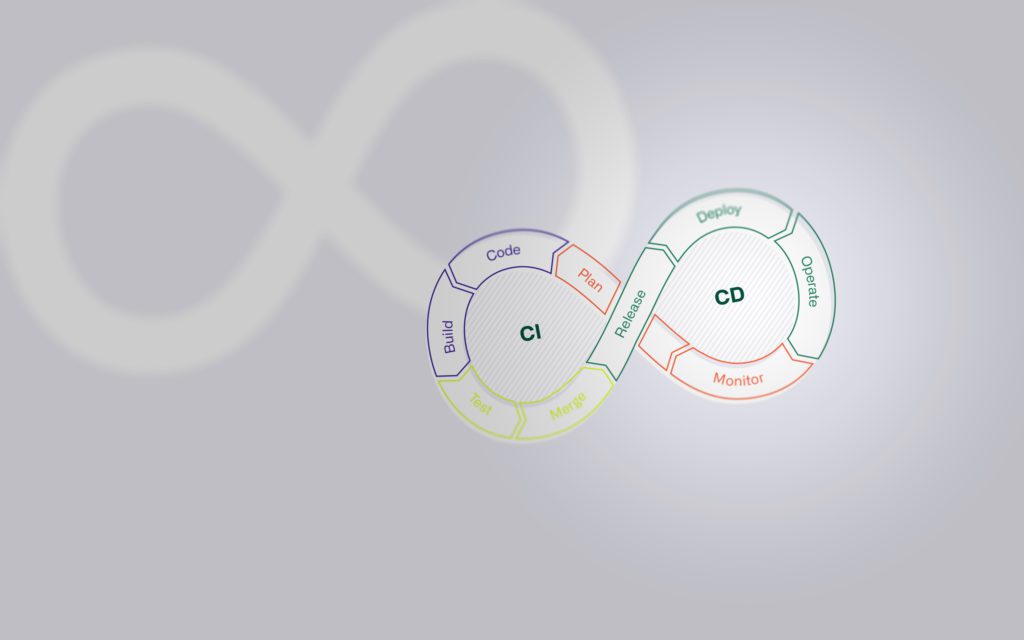
Erfahren Sie mehr über Verteilungsansätze und CI/CD in unserem Blogbeitrag über CI/CD und IaC
CI/CD und IaC
von Thomas Somogyi
Fehlerbehebung durch integriertes Monitoring
Die Vorbereitungen wurden abgeschlossen, die Container-Infrastruktur wurde aufgebaut und die Applikation kann über das Orchestrierungstool verwaltet werden. Nun gilt es, den Betrieb der Applikation zu sichern und zu überwachen, um diese später in den produktiven Tagesbetrieb zu übernehmen.
Hier bietet ein Orchestrierungstool wie Kubernetes eingebaute Monitoring-Funktionalitäten, welche es ermöglichen, Daten und Logs im Tagesbetrieb zu sichern.
Aktive Container sammeln während des Betriebs regelmässig Nutzungsdaten, aus denen sich mittels Analysen Verbesserungspotenziale zur Infrastruktur oder am darunterliegenden Microservice ziehen lassen. Diese Log-Daten können ebenfalls für das Bugfixing des Services durch Entwickler verwendet werden. Aufgrund der Abkapselung und Isolation der Applikation in die einzelnen Container lassen sich Ursachen von Fehlerquellen schnell erkennen und beheben.
Weitere Herausforderungen in der Containerisierung
Im Rahmen eines Kundenprojekts hat die atrete eine schweizerische Bank dabei unterstützt, die Zielarchitektur einer containerbasierten Applikationslandschaft zu definieren. Während dieses Vorhabens haben wir verschiedene Stolpersteine und Herausforderungen gemeistert.
Hier sind einige der gängigsten Fälle, die während der Konzipierungsphase im Projekt aufgetreten sind:
- Die Integration von containerbasierten Applikationen mit Legacy-Systemen stellt oft eine Herausforderung dar, besonders wenn dabei File Transfer Technologien zum Einsatz kommen, die auf Agents basieren. In vielen Fällen sind spezielle Lösungen erforderlich, um diese Technologien für den Einsatz in der Container-Welt anzupassen.
- Container sind in der Regel flüchtig, was bedeutet, dass Daten verloren gehen können, wenn ein Container gelöscht wird. Für Anwendungen, die eine Datenpersistenz benötigen, muss eine Strategie zur Datenspeicherung und -verwaltung ausserhalb der Container entwickelt werden. Eine derartige Strategie sollte sich im Design der Zielarchitektur widerspiegeln.
- Obwohl Container-Technologien bereits seit einiger Zeit eingesetzt werden, sind viele Menschen in deren Handhabung noch nicht versiert und benötigen entsprechende Schulungen, um zu lernen, wie solche Applikationen betrieben werden können. Dies trifft insbesondere auf die erstmalige Einrichtung einer containerbasierten Applikation zu, bei der spezifisches Know-how erforderlich ist.
Unser Fazit
Durch Containerisierung lassen sich Applikationen skalieren, einfacher verwalten und Entwicklungsprozesse im Betrieb weiter automatisieren. Bevor man von diesen Vorteilen profitieren kann, ist ein variabler Initialaufwand notwendig. Dieser Aufwand beschränkt sich darauf, die zu migrierende Applikation zu verstehen, um darüber urteilen zu können, welche Abhängigkeiten, Komponenten und Sicherheitsaspekte von Bedeutung sind. Die Höhe des Aufwands hängt von der Grösse, Komplexität und den Anforderungen an die Applikation ab. Wir denken, dass besonders bei hochkomplexen Applikationen eine Detailstudie zur Machbarkeit einer Containerisierung notwendig ist, bei deren Erarbeitung wir Ihr Unternehmen unterstützen können.
Für die Konzeption und Umsetzung von Containerisierung bestehen Best Practices. Hierbei empfehlen wir auf bewährte Ansätze gängiger Hersteller wie Docker für die Implementation oder Kubernetes für die Orchestrierung zu setzen.
Bei den einzelnen Schritten im Migrationsprozess ist unserer Meinung nach besonders die Zielarchitektur massgebend.
Eine falsche oder fehlerhafte Definition der Container-Infrastruktur kann negative Auswirkungen auf die Implementierung und den langfristigen Betrieb haben. Beispielsweise kann eine erhöhte Komplexität durch zu viele Abhängigkeiten entstehen oder es können Leistungsprobleme durch überdimensionierte Images auftreten. Ausserdem soll für die Auswahl einer Containerisierungs-Technologie geprüft werden, welches unternehmensinterne Knowhow zu welcher Technologie bereits vorhanden ist, um potenzielle Synergieeffekte nutzen zu können. Die Technologieauswahl soll ein Orchestrierungstool enthalten, mit welchem die Container-Infrastruktur modular strukturiert, gemonitort und verwaltet werden kann.
Anhand der Erkenntnisse und Resultate aus der Analyse- und Planungsphase kann ermittelt werden, welches die grössten Vorteile sind, die ein Unternehmen aus der Containerisierung von Applikationen ziehen kann. Eine Container-Infrastruktur lässt sich nach dem Initialaufbau durch ein etabliertes Vorgehen und definierten Richtlinien zukunftssicher ausbauen.
Gerne unterstützen wir Sie und begleiten Sie auf Ihrem Weg durch die Welt der Containerisierung.
Lancierung neuer Practice Areas
atrete IT Consultants führt zwei neue Practice Areas ein, um den Kundenanforderungen im Bereich der digitalen Transformation gerecht zu werden.
at rete ag (atrete), ein führendes Schweizer Unternehmen im Bereich der IT-Beratung, hat heute eine strategische Neuausrichtung angekündigt, um die digitale Transformation bei ihren Kunden voranzutreiben und weitere innovative Beratungsdienstleistungen anzubieten, die den ständig wachsenden, organisatorischen und technischen Herausforderungen in der Informationssicherheit und der IT gerecht werden.
Im Zuge dieser Entwicklung hat atrete zwei neue Consulting Practice Areas eingeführt, um die Bedürfnisse ihrer Kunden noch besser zu erfüllen: „data, automation & AI“ sowie „migration & operations“. Diese beiden Fachbereiche sind speziell darauf ausgerichtet, die digitalen Transformationen ihrer Kunden zu unterstützen und innovative Beratungsleistungen anzubieten, die ihre geschäftlichen Ziele vorantreiben.
Die Practice Area „data, automation & AI“ konzentriert sich darauf, Unternehmen dabei zu helfen, ihre Daten optimal zu nutzen, Automatisierungsprozesse zu implementieren und künstliche Intelligenz einzusetzen, um Einblicke zu gewinnen und betriebliche Abläufe zu optimieren.
Die Practice Area „migration & operations“ unterstützt Unternehmen bei der reibungslosen Transition ihrer IT-Infrastruktur und -Anwendungen sowie bei der Optimierung und dem Betrieb ihrer digitalen Umgebungen.
Weiterhin bietet atrete ihre bewährten Beratungsdiensleistungen für CIOs, Beschaffungen, Informationssicherheit, Hybride Cloud und Connectivity Infrastrukturen, sowie Digital Workplace und Kollaborationslösungen an.
„Bei atrete IT Consultants haben wir es uns zum Ziel gesetzt, unseren Kunden dabei zu helfen, sich den Herausforderungen der digitalen Ära erfolgreich zu stellen“, sagte Michael Kaufmann, CEO bei atrete. „Wir gehen gemeinsam mit unseren Kunden. Digitalisierung, Informationssicherheit, Automatisierung sind entscheidende Schritte auf diesem Weg.“
atrete IT Consultants freut sich darauf, mit ihren Kunden zusammenzuarbeiten, um ihre digitale Transformation voranzutreiben und ihnen dabei zu helfen, innovative Lösungen zu implementieren, die ihre Geschäftsziele unterstützen.
Kontakt:
at rete ag
Marlene Haberer
Telefon: +41 44 266 55 83
Email: marlene.haberer@atrete.ch
Effizienz durch Automation
Um immer wiederkehrende IT-Infrastruktur Aufgaben mit gleichbleibend hoher Qualität und möglichst geringem Aufwand durchführen zu können, ist eine Automation solcher Abläufe unabdingbar.
Um erfolgreich solche “IT-Produkte” herstellen zu können, sind gewisse Vorbedingungen elementar wichtig. Wie z.B. klare detaillierte Vorstellungen des Endproduktes, einheitliche Konzepte, klare Definition der variablen Elemente und gute, vollständige Inventardaten.
Aussagen wie «wir wissen zwar noch nicht, wie das Produkt aussehen soll, wir werden dessen Herstellung jedoch auf jeden Fall automatisieren, um den Aufwand in Grenzen zu halten, beginnt doch mal mit den Überlegungen, wie eine Automatisierung aussehen könnte» ist als Basis für eine Automation nicht zielführend. Automatisierung ist ein evolutionärer Prozess, welcher durchlaufen wird, in welchem es wichtig ist, dass die Skills der Mitarbeitenden mit der zunehmenden Komplexität wachsen können.
In den folgenden Abschnitten werden wir auf wichtige Punkte, welche als Voraussetzung für eine erfolgreiche Automatisierung gelten, näher eingehen.
Low Level Design und Anzahl der Ausprägungen
Es muss in allen Details klar sein, wie das Produkt in allen seinen Ausprägungen aufgebaut werden soll. Die Anzahl unterschiedlicher Ausprägungen soll möglichst klein gehalten werden. Dabei wird oft der Begriff «T-Shirt Sizes» verwendet. Dieser Begriff impliziert gut, dass nicht beliebig viele Ausprägungen eines Produkts existieren sollen.
Der Schlüssel liegt in durchdachten Konzepten
Neben dem Blueprint sind in der Regel vielerlei Konzepte notwendig. Zum Beispiel Namens-, IP-Adress- und VLAN-Konzepte, um nur einige zu nennen. Bei den Konzepten ist darauf zu achten, dass die Werte für die verschiedenen Parameter berechnet werden können, ggf. müssen bestehende Konzepte dahingehend angepasst werden.
Kunden- und Factory-Seite beachten
Ein Automatisierungslösung hat immer zwei Seiten. Man spricht von den Kunden- und der Factory-Seite. Die Kundenseite bildet der Presentation Layer und es ist das wesentliche Element, das den Benutzer nicht überfordern darf, ihn unterstützt seine Angaben möglichst strukturiert und validiert zu erfassen. Der Presentation Layer ist eine definierte Bestelloberfläche für den Kunden und stellt die Integration ins Datenmanagement sicher.
Auf Factory-Seite wird der Orchestration Layer betrachtet, der alle Daten zur Herstellung des Produkts notwendigen Parameter und deren Werte liefert, um dieses möglichst automatisiert herzustellen, respektive auszurollen. Die Orchestration Layer kann auf verschiedenen Stufen abgebildet sein. Im einfachsten Fall werden Automatismen mit Scripts gesteuert. Eine weitere Stufe ist, dass bestehende Process Automation genutzt und mit Business Logiken versehen werden. Im fortgeschrittenen Fall kann ein oder mehrere bestehende Tools auf die Unternehmensbedürfnisse und Prozesse angepasst und deren APIs verwendet werden.
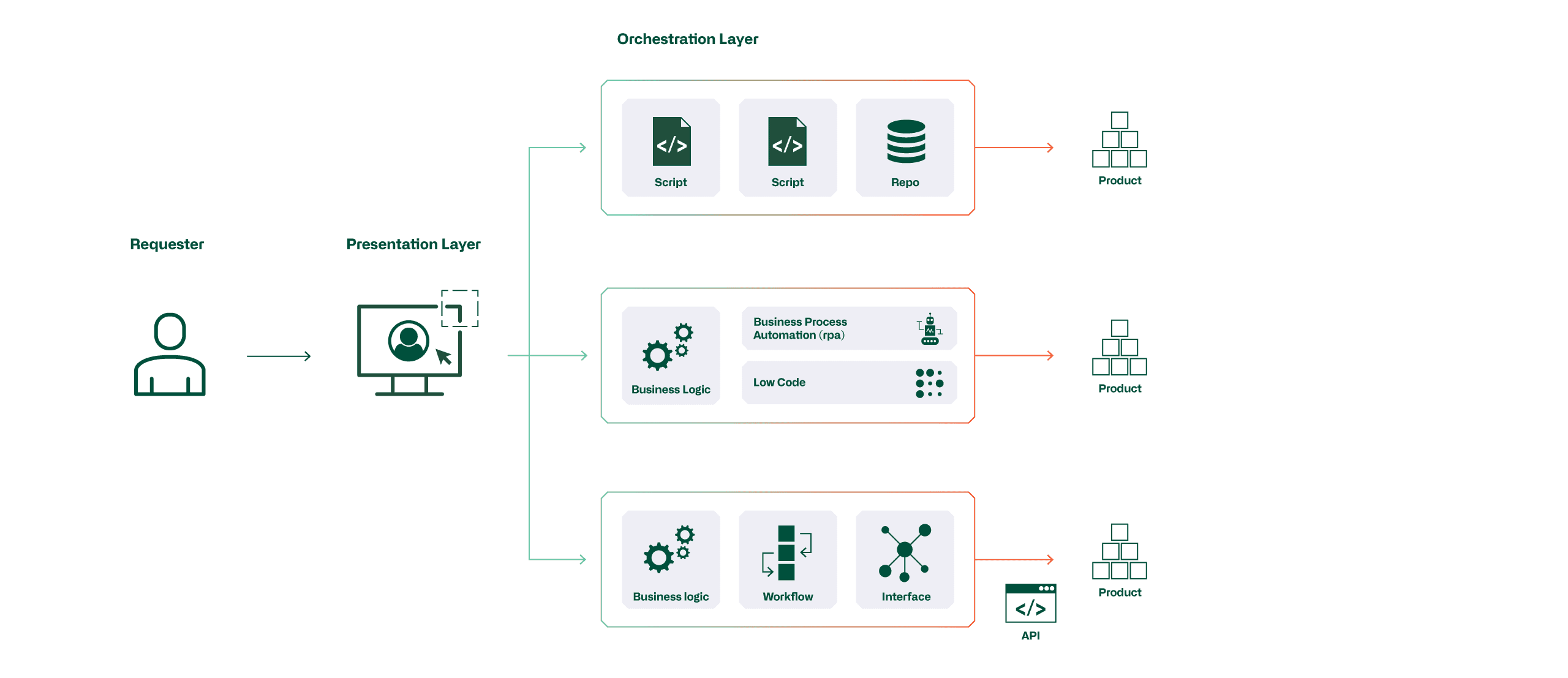
Datenquellen organisieren
Alle Daten, der zur Herstellung eines Produkts notwendigen Parameter, müssen auf irgendeinem System zur Verfügung stehen. Sollten diese auf mehreren Systemen verfügbar sein, muss klar sein, welches das führende System ist und wer für die Daten verantwortlich ist. «Single Source of Truth» heisst nicht, dass alle Daten auf einem System verfügbar sein müssen. Als Beispiel werden VLAN-Nummern und IP-Adressen von einem IP-Adress-Management System bezogen, während die Standort-Adressen, an welcher ein Gerät installiert werden soll, aus dem ERP stammen.
Fazit
Es gibt nicht “Die Automation”. In jeder Firma sind die Voraussetzungen und Bedürfnisse bestehend Automation sehr unterschiedlich. Dies insbesondere auch im Bereich der vorhandenen Skills der IT-Infrastruktur Teams, welche historisch nur wenige Softwareengineers und Programmierer enthalten.
Wichtig ist, sich dem Thema der Automatisierung vom Kleinen zum Grossen zu nähern und sich das notwendige Skill-Set zu erarbeiten, um so an den Aufgaben zu wachsen und diese auch erfolgreich abschliessen zu können.
Unsere Spezialisten haben in diversen Automatisierungsprojekten von der Konzeptionierung bis zur Einführung das erforderliche Know-how aufgebaut und weiterentwickelt. Wir unterstützen unsere Kunden, um die Voraussetzungen zur Automation in einem Review zu eruieren.
Automation
Aufgrund der agilen Vorgehensweisen in vielen IT-Bereichen und um den dadurch resultierenden kürzeren Bereitstellungszeiten von IT-Infrastruktur nachzukommen, denken viele IT-Organisationen darüber nach, was mit vertretbarem Aufwand automatisiert werden könnte, um die wachsenden Anforderungen seitens des Business zu erfüllen.
Neben der Agilität sind es auch die Kosten und nicht zuletzt die geforderte Qualität, welche der Automatisierung Vorschub leisten. Ist ein Ablauf einmal automatisiert, dann können auch anders qualifizierte IT-Mitarbeiter, oder im besten Falle der Besteller eines Services selbst, diesen Schritt durchführen, was sich schlussendlich auch positiv auf die Kosten auswirkt.
Bedingungen
Um einen Vorgang automatisieren zu können, muss dieser zwingend standardisiert sein, also mit möglichst wenigen Ausnahmen immer gleich ablaufen. Zudem muss dieser Vorgang häufig angefordert und durchgeführt werden, um den Aufwand einer Automatisierung zu rechtfertigen.
Eine Automatisierung erfordert zudem, dass die IT-Infrastruktur in den Bereichen Compute, Storage und Netzwerk virtualisiert ist. Wenn jedes Mal, wenn eine zusätzliche Instanz eines Service im Datacenter aufgeschaltet werden soll, Hardware angeschafft und installiert werden muss, kann nicht automatisiert werden.
Art der Automation
Es wird zwischen der vertikalen und der horizontalen Automatisierung unterschieden. Diese Grafik zeigt den Unterschied.
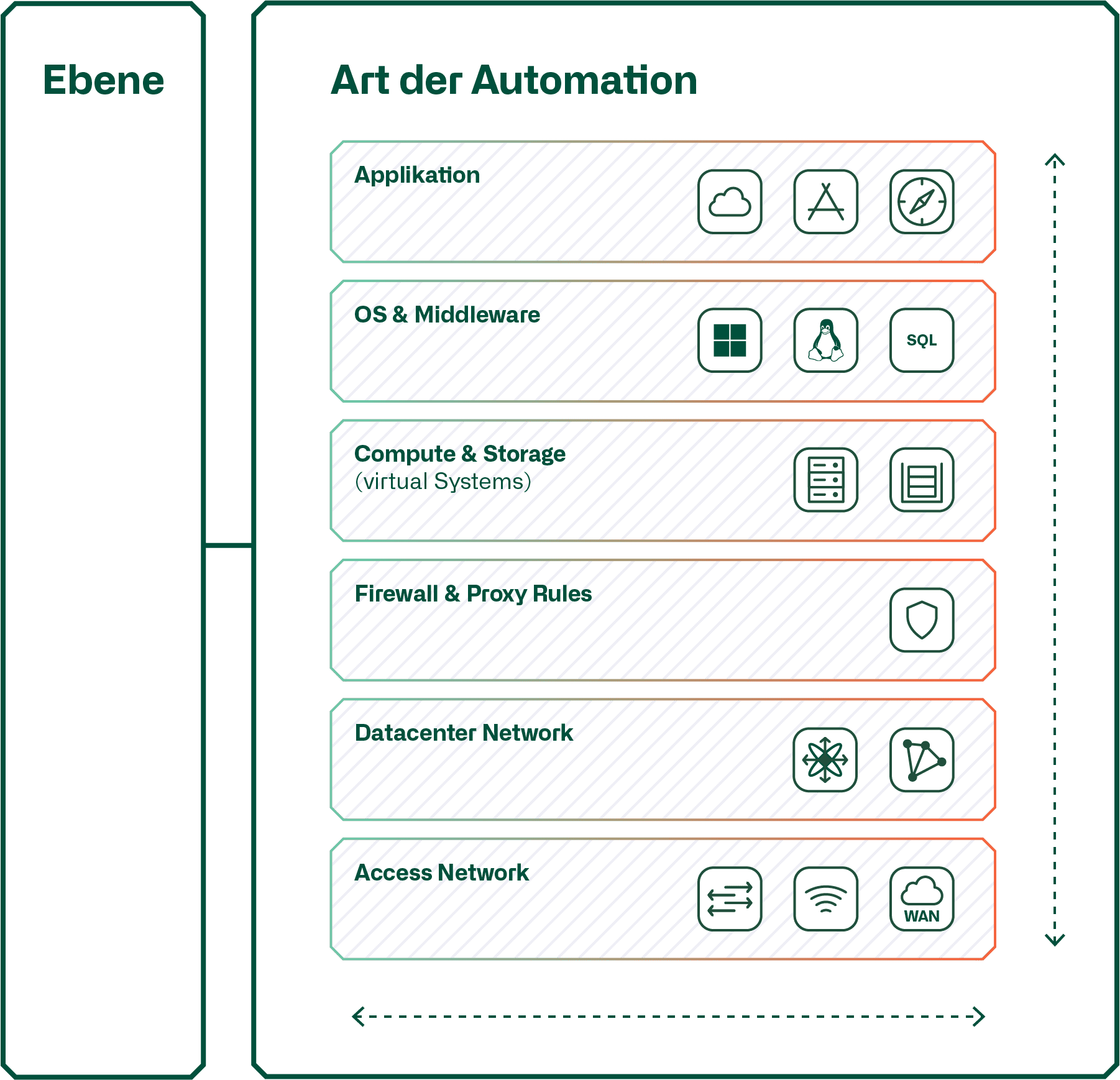
Bei der horizontalen Automation werden die Vorgänge beschränkt auf die jeweilige Ebene automatisiert. Hier als Beispiel das Datacenter Netzwerk, welches mit einer «out of the Box» SDN-Lösung eines Netzwerkherstellers automatisiert wird. Oder die Ebene «Firewall & Proxy Rules» wird mit einem Firewall-Policy-Management automatisiert. Das Gleiche gilt für die Ebene «Compute & Storage», welche mit den Automatisierungstools der Lieferenten der Virtualisierung von Compute oder Storage automatisiert werden.
Erst wenn die einzelnen Ebenen ausreichend automatisiert sind, kann eine vertikale Automatisierung realisiert werden, um Instanzen eines multilayer Service, also eines Service, welcher aus Services verschiedener Ebenen besteht, automatisiert zu provisionieren. Oftmals spricht man im Falle der vertikalen Automatisierung auch von Orchestrierung. Eine vertikale Automatisierung bedingt, dass die zur Automatisierung einer Ebene eingesetzten Produkte ein «Northbound API» aufweisen. Dieses wird vom Orchestrator der vertikalen Automatisierung verwendet, um Instanzen in der entsprechenden Ebene zu provisionieren. Zum Beispiel, um auf der Ebene «Datacenter Network» einen virtuellen Router mit den dazugehörenden VLANs zu konfigurieren, mit welchen der Orchestrator in einem weiteren Schritt die VMs via dem Compute Automatiserungstool verbindet.
Architektur Automatisierungstools
Die Automatisierungstools einer Ebene weisen alle in etwa dieselbe Architektur aus. Diese ist in der folgenden Grafik dargestellt.
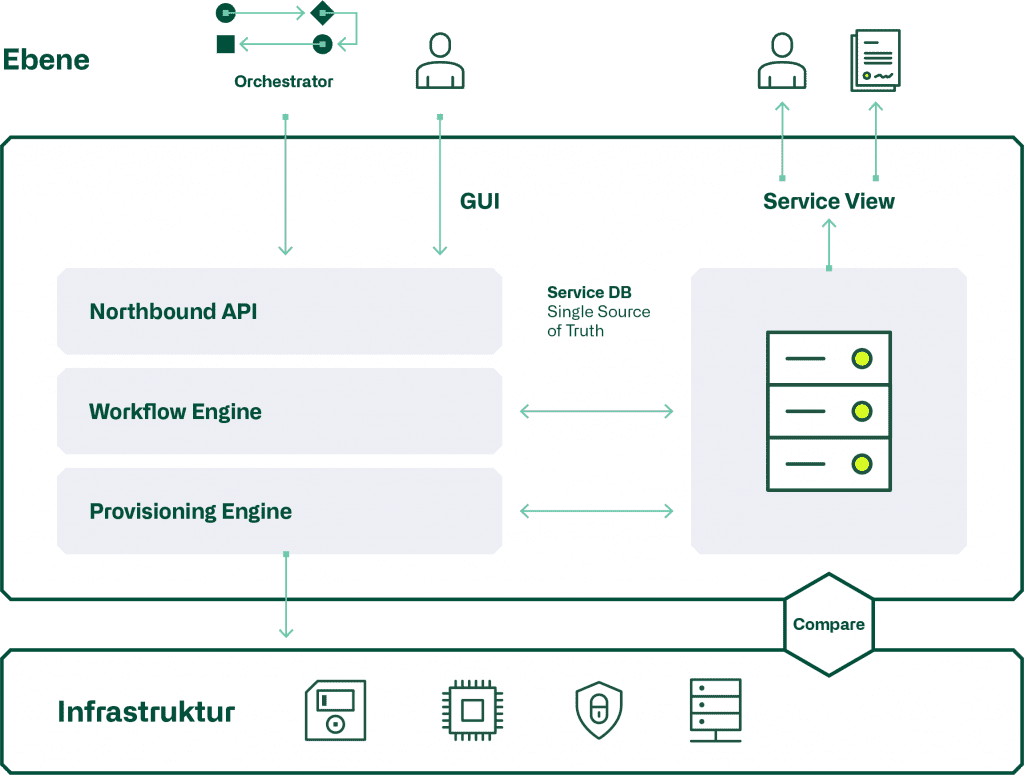
Beginnen wir mit dem «Northbound API», welches verwendet wird um die Services einer Ebene zu konfigurieren. Dies geschieht entweder mittels dem GUI durch eine Person, oder direkt durch den Orchestrator der vertikalen Automation. Entscheidend ist hier, dass auch das GUI das «Northbound API» verwendet, da so sichergestellt ist, dass alle GUI Funktionen auch den Orchestrator zur Verfügung stehen.
Die «Workflow Engine» führt die verschiedenen Schritte durch, welche den Service ausmachen. Anschliessend erstellt die «Provisioning Engine» die zur Konfiguration notwendigen «Snipplets», welche dann via Rest-API, Netconf oder CLI auf die Komponenten der Infrastruktur provisioniert werden. Die Struktur und die Parameter eines Service werden in der Service DB festgehalten, welche immer den «Single Source of Truth» darstellt.
In einer Model-Driven Automatisierung werden die Konfigurationen der Infrastrukturkomponenten periodisch. mit der Service DB abgeglichen. Hier stellt sich die Frage, wie mit den Abweichungen umgegangen wird. Oftmals wird nur ein Reporting erstellt und die Differenzen müssen manuell bereinigt werden, da ein direktes Reprovisioning aus der Service DB einen Unterbruch des betroffenen Service zur Folge haben könnte.
Zudem kann aus der Service DB mittels dem «Service Viewer» die Service-Struktur und die -Parameter in der Form eines Service-Tree direkt online, oder als Report dargestellt werden. Dies ist ein wichtiges Feedbackinstrument, um die korrekte Funktion der Workflow- und der Provisionig-Engine zu überprüfen.