Containerization of an application
Containerization allows program code to be bundled, distributed in isolated environments, patched and scaled. The development and provision of applications is simplified and structured in a modular way. Despite its many advantages, however, containerization does not always make sense, as the path to an optimal container infrastructure can be long and rocky without a plan.
In this blog, we present the steps required to containerize an application, the benefits of doing so and when containerization should be considered. We also highlight important aspects that need to be considered when containerizing an application in order to successfully implement and operate containers.
Containerization concept
Containerization allows applications to be broken down into "containers". This allows program code within a container, including its dependencies (libraries, frameworks, other files), to be bundled as a separate software package and executed as a process. The bundling of such a software package takes place in the form of images, which are provided via Docker, for example.
Another feature of containers is their use as a lean alternative to conventional virtual machines, as they do not require their own operating system for operation. They use the operating system kernel of their host system to run processes. All containers within a container infrastructure share the same kernel of a central host system, but have no access to their neighbouring containers.
The shared operating system kernel ensures that a containerized application can be executed in the same context regardless of the platform.
Why containerize?
The question now arises as to why software development companies should break down their applications into their individual parts at all. The benefits must cover the costs in order to justify the move towards containerization.
The containerization of an application offers the following advantages over the classic, usually monolithic approach, with which the application is operated in one or more virtual machines:
- Reduced operating costs
Omitting a separate operating system saves storage space, computing power and resources. A container image only needs enough power to run the processes within its software package. - Scalability
Containers can be started and stopped within a short time. If more computing power is required for an application, new containers can be set up within a very short time by providing an image. This enables a high degree of scalability. - Portability
The modular nature of a container means that it can be deployed and migrated to new infrastructures in isolation. This is practical in the case of an upcoming cloud journey, for example, in which parts of a containerized application are migrated from an on-premises landscape to a cloud environment. It should also be mentioned here that most SaaS solutions are based on containerized backend software modules. - Performance
With conventional approaches to virtualization, a certain amount of a system's performance is always lost for the operation of the operating system.
A container is there to execute processes for which it was created. Due to this isolation, the entire computing power within a container can be allocated to the execution of the processes. - Consistency
In view of the fact that all containers use the same operating system kernel of their host system, the kernel also forms the same basis for the functionality and operating environment of the containers. This significantly simplifies the development and deployment of an application because its containerized modules function in the same way in all environments. - Optimized for modern DevOps approaches
DevOps creates the premise of being able to guarantee continuous and immediate integration of code into existing environments. Using orchestration tools such as Kubernetes, DevOps teams can deploy, version and rollback individual containers or entire containerized applications within a short space of time. The entire life cycle of an application can therefore be controlled and managed using DevOps.
From legacy application to container infrastructure
Due to the many direct advantages of containerization and the ongoing urge of companies to modernize their legacy systems, which is reinforced by trends such as cloud computing, the question now arises:
Why aren't all companies starting to run their applications as containers? Answering this question is also the first step on the path to containerizing an application.

Analysis and planning phase
Before considering containerization, an understanding of the application in question must be created in advance. "Creating understanding" means becoming aware of the components that make up the application to be migrated, what its architecture looks like and how the complexity of a decomposition is assessed. For example, it makes little sense to containerize a highly complex application that consists of numerous components including dependencies. The aim of containerization is to simplify the operation and management of an application, not to make it worse.
To avoid such cases, it is important to clarify the following questions:
- Is it possible to divide the application into logical, functional areas?
- Can these areas be isolated in a container?
- Roughly how many containers would the application consist of?
In addition to the management aspects that need to be considered when evaluating containerization, there are also security aspects that need to be taken into account. While the shared kernel is very advantageous for operation and performance compared to conventional operating system VMs, this infrastructure circumstance also poses an increased security risk in the event of a cyber attack. For example, the possibility of an attack on the kernel of the host system creates an attack surface for all containers within a containerized application of the same container host system.
In the analysis phase, it is imperative to thoroughly analyse such consequences and such risks and possible consequences in advance in order to be able to take appropriate security measures.
Technology selection
After a positive evaluation of an application with regard to containerization, the next step is to select a suitable container technology. Before selecting the technology, the infrastructure environment must also be defined: On-premises or cloud?
The choice between the two options depends on the requirements for the application to be containerized, which arise during the analysis phase. Important considerations here are, for example, the requirements for scalability, security, availability and costs. Accordingly, an evaluation of the advantages and disadvantages of each environment is required in order to be able to make a decision.
For this blog, we will choose the implementation principle called Docker as the container technology. Docker is particularly known for its simplicity and efficiency and has established itself as the industry standard for containerization.
Recognize dependencies
Identifying dependencies of the application is the next step in the analysis phase and is the prerequisite for defining a target architecture. Dependencies are elements such as external libraries, user-defined frameworks or configuration files that form part of the container image. External services such as databases and API interfaces are usually operated outside the container. The distinction between external components and parts of the container image is necessary in order to configure a container-based application correctly.
Data within a container image is usually volatile and non-persistent compared to data obtained from external databases and interfaces. The dependencies listed must be taken into account when segmenting the application into individual services.
Define target architecture
The target architecture of the container infrastructure is defined based on the selected technology and the identified dependencies. At this point, we would like to draw particular attention to the choice of location for the application data. It is of central importance to define in the target architecture what type of data will be stored where after a possible division of the application. A (containerized) application in the cloud has different security requirements than an application that is located on-premises. A container that processes strictly confidential data within the application does not have the same security requirements as a container that only hosts the user interface of a web portal.
Prioritization of services
The results from the analysis phase and the defined target architecture enable reliable prioritization, which determines the order in which existing services are migrated to the new container infrastructure. The prioritization criteria are made up of different factors. These factors must be weighted accordingly. The weighting is based on the defined requirements and the characteristics of the application.
- Relevance of the service in relation to business processes
- Technical complexity of the service structure
- Amount of the estimated expense for containerization
- Degree of security
- Etc.
Prepare and implement
Once the work in the analysis and planning phase has been completed, the transition to a container-based architecture takes place. This begins with the installation and setup of the platform, defined according to the target architecture. At the heart of this phase is the creation and configuration of the Docker images for the individual containers and other artefacts that form the basis for the containerized application.
Containerization process
The process behind the creation of container images depends on the selected technology. Based on Docker, this starts with the creation of a file for the composition of the Docker setup. This file is called a "Dockerfile". A "Dockerfile" is a text-based configuration file in YAML notation that contains all the commands in a specific order to create a container image. When creating the Dockerfile, it is also important to add versioning tags to it. Versioning tags can be used to provide container images with information that helps application developers to distinguish between test and production images.
The container images are divided and organized according to the individual microservices, as defined in the previous phase. Once the container image has been successfully created, it can be tested directly within Docker. After a successful test phase, the Docker image can either be stored in a location specifically designated for the target architecture or in a container registry. The number of Docker images and containers required for an application depends on the defined target architecture and its components. The finished container images can then be made available via a container orchestration platform as the basis for executable containers.
Container orchestration
A container orchestration tool is a system for the management, deployment and operation of containers. Container orchestration allows containers to be scaled, organized and deployed to their intended platforms in the shortest possible time. Container orchestration tools also make it possible to track the utilization, computing power and availability of containers, which is why they are also used to monitor them. One of the leading orchestration tools for containers is Kubernetes. Kubernetes enables the management of clusters consisting of nodes:

The nodes in Kubernetes can be physical or virtual machines. They are the work units that execute, scale and monitor the containers. A Kubernetes cluster consists of at least one master node, which is responsible for orchestrating and managing the cluster, and several worker nodes on which application(s) run in containers.
The use of nodes within Kubernetes enables control over resources and offers high availability through replication. With features such as automatic scaling, an application can be dynamically scaled based on its workload to ensure resource efficiency and optimal performance.
It is essential to use an orchestration tool when setting up a container-based infrastructure in order to maintain and simplify the overview of all containers as an application landscape grows. As it is in the nature of orchestration tools to automate several manual processes in container deployment, they are also perfectly suited for the implementation of modern DevOps approaches through CI/CD pipelines.
Integration and operation
Integration of CI/CD and devops through orchestration
The entire containerization process can be automatically integrated into new or existing DevOps practices using container orchestration and CI/CD pipelines during day-to-day operations. This not only simplifies the deployment, but also the maintenance of the containerized application considerably. New builds of a container image can be tested on existing or new containers and deployed productively within a few minutes using preconfigured build pipelines.
A containerized application is particularly suitable for distribution approaches such as blue-green deployment because containers can be deployed quickly and consistently without disrupting data traffic. The isolation and security of containers minimizes the susceptibility to errors and enables simple rollbacks to previous versions if problems occur. In addition, containers optimize the use of resources, which is particularly advantageous when running multiple versions of an application in parallel, as is the case with blue-green deployment.
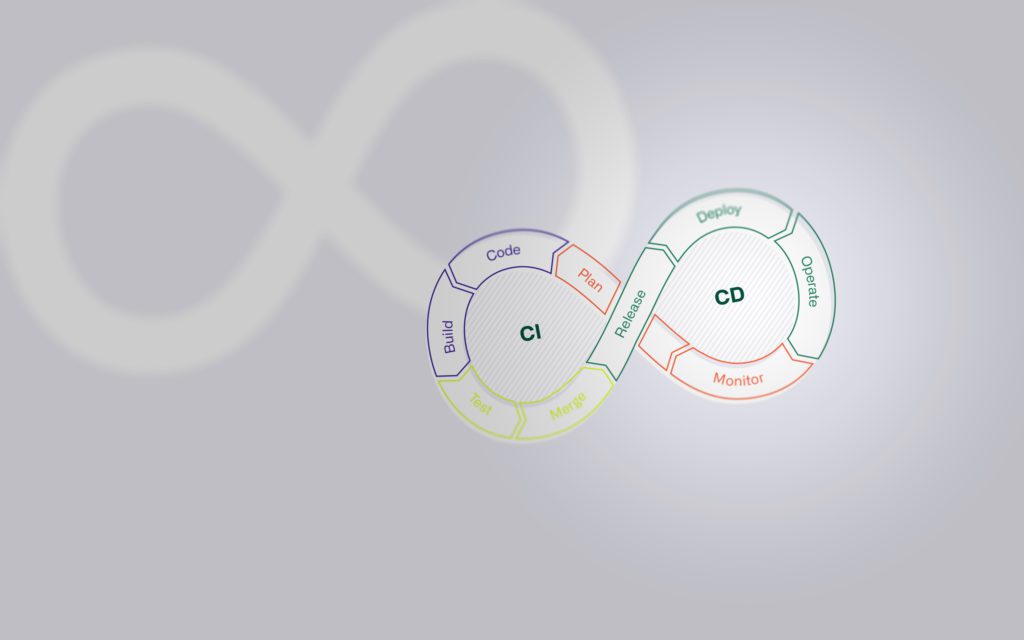
Learn more about distribution approaches and CI/CD in our blog post about CI/CD and IaC
CI/CD and IaC
from Thomas Somogyi
Troubleshooting through integrated monitoring
The preparations have been completed, the container infrastructure has been set up and the application can be managed via the orchestration tool. The next step is to secure and monitor the operation of the application so that it can later be transferred to productive daily operation.
This is where an orchestration tool such as Kubernetes offers built-in monitoring functionalities that make it possible to secure data and logs during daily operation.
Active containers regularly collect usage data during operation, which can be analyzed to identify potential improvements to the infrastructure or the underlying microservice. This log data can also be used by developers for bugfixing the service. Due to the encapsulation and isolation of the application in the individual containers, the causes of errors can be quickly identified and rectified.
Further challenges in containerization
As part of a customer project, atrete supported a Swiss bank in defining the target architecture of a container-based application landscape. During this project, we overcame various stumbling blocks and challenges.
Here are some of the most common cases that arose during the design phase of the project:
- The integration of container-based applications with legacy systems is often a challenge, especially when file transfer technologies based on agents are used. In many cases, special solutions are required to adapt these technologies for use in the container world.
- Containers are usually volatile, which means that data can be lost if a container is deleted. For applications that require data persistence, a strategy for data storage and management outside the containers must be developed. Such a strategy should be reflected in the design of the target architecture.
- Although container technologies have been in use for some time, many people are not yet familiar with their use and require appropriate training to learn how to operate such applications. This is particularly true when setting up a container-based application for the first time, where specific know-how is required.
Our conclusion
Containerization allows applications to be scaled, managed more easily and development processes to be further automated during operation. Before you can benefit from these advantages, a variable amount of initial effort is required. This effort is limited to understanding the application to be migrated in order to be able to assess which dependencies, components and security aspects are important. The amount of effort required depends on the size, complexity and requirements of the application. We believe that a detailed study on the feasibility of containerization is necessary, especially for highly complex applications, and we can support your company in developing this.
Best practices exist for the design and implementation of containerization. We recommend relying on proven approaches from established manufacturers such as Docker for implementation or Kubernetes for orchestration.
In our opinion, the target architecture is particularly important for the individual steps in the migration process.
An incorrect or faulty definition of the container infrastructure can have a negative impact on implementation and long-term operation. For example, increased complexity can arise due to too many dependencies or performance problems can occur due to oversized images. In addition, when selecting a containerization technology, it is important to check which internal company expertise is already available for which technology in order to take advantage of potential synergy effects. The technology selection should include an orchestration tool with which the container infrastructure can be modularly structured, monitored and managed.
The findings and results from the analysis and planning phase can be used to determine the greatest benefits that a company can derive from containerizing applications. After the initial setup, a container infrastructure can be expanded in a future-proof manner using an established procedure and defined guidelines.
We are happy to support you and accompany you on your journey through the world of containerization.
Launch of new practice areas
atrete IT Consultants is introducing two new practice areas to meet customer requirements in the area of digital transformation.
at rete ag (atrete), a leading Swiss IT consulting company, today announced a strategic realignment to drive digital transformation for its clients and offer further innovative consulting services to meet the ever-growing organizational and technical challenges in information security and IT.
As part of this development, atrete has introduced two new consulting practice areas to better meet the needs of its clients: "data, automation & AI" and "migration & operations". These two practice areas are specifically designed to support their clients' digital transformations and provide innovative consulting services that drive their business goals forward.
The "data, automation & AI" practice area focuses on helping companies make the most of their data, implement automation processes and use artificial intelligence to gain insights and optimize operational processes.
The "migration & operations" practice area supports companies in the smooth transition of their IT infrastructure and applications as well as in the optimization and operation of their digital environments.
Furthermore, atrete offers its proven consulting services for CIOs, procurement, information security, hybrid cloud and connectivity infrastructures, as well as digital workplace and collaboration solutions.
"At atrete IT Consultants, we have made it our goal to help our customers successfully meet the challenges of the digital era," said Michael Kaufmann, CEO at atrete. "We walk together with our customers. Digitalization, information security and automation are decisive steps on this path."
atrete IT Consultants looks forward to working with its clients to drive their digital transformation and help them implement innovative solutions that support their business goals.
Contact:
at rete ag
Marlene Haberer
Phone: +41 44 266 55 83
Email: marlene.haberer@atrete.ch
Efficiency through automation
In order to be able to perform recurring IT infrastructure tasks with consistently high quality and as little effort as possible, automation of such processes is indispensable.
In order to be able to successfully manufacture such "IT products", certain preconditions are elementarily important. Such as clear detailed ideas of the end product, uniform concepts, clear definition of variable elements and good, complete inventory data.
Statements such as "we don't yet know what the product will look like, but we will definitely automate its manufacture in order to keep the effort within limits, so why don't you start thinking about what automation might look like" is not a useful basis for automation. Automation is an evolutionary process that is run through, in which it is important that the skills of the employees can grow with the increasing complexity.
In the following sections, we will go into more detail on important points that are considered prerequisites for successful automation.
Low level design and number of expressions
It must be clear in all details how the product is to be structured in all its manifestations. The number of different characteristics should be kept as small as possible. The term "T-shirt sizes" is often used here. This term implies that there should not be an unlimited number of versions of a product.
The key lies in well thought-out concepts
In addition to the Blueprint, many different concepts are usually necessary. For example, name, IP address and VLAN concepts, to name just a few. In the case of the concepts, care must be taken to ensure that the values for the various parameters can be calculated; if necessary, existing concepts must be adapted to this end.
Observe customer and factory side
An automation solution always has two sides. We speak of the customer side and the factory side. The customer side is formed by the presentation layer, and it is the essential element that must not overburden the user, but supports him in entering his data in as structured and validated a manner as possible. The presentation layer is a defined ordering interface for the customer and ensures integration into the data management system.
On the factory side, the orchestration layer is considered, which supplies all the data required for manufacturing the product and its values in order to manufacture or roll it out as automatically as possible. The orchestration layer can be mapped at different levels. In the simplest case, automatisms are controlled with scripts. Another level is that existing process automation is used and provided with business logics. In the advanced case, one or more existing tools can be adapted to the business needs and processes and their APIs used.
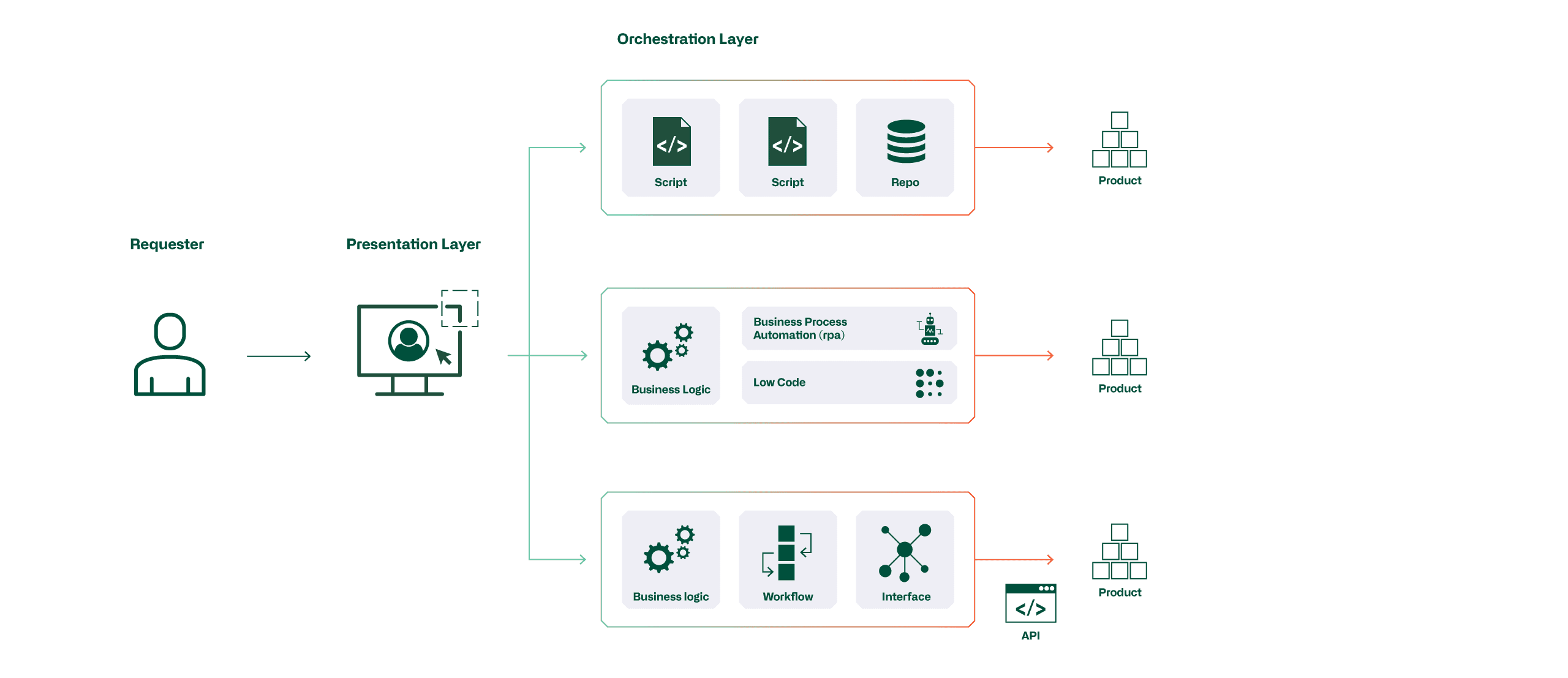
Organize data sources
All data of the parameters necessary for the manufacture of a product must be available on some system. If they are available on several systems, it must be clear which is the leading system and who is responsible for the data. "Single source of truth" does not mean that all data must be available on one system. As an example, VLAN numbers and IP addresses are obtained from an IP address management system, while the site addresses where a device is to be installed come from the ERP.
Conclusion
There is no such thing as "the automation". In every company, the requirements and needs for automation are very different. This is especially true in the area of the existing skills of the IT infrastructure teams, which historically contain only a few software engineers and programmers.
It is important to approach the topic of automation from the small to the large and to acquire the necessary skill set in order to grow with the tasks and to be able to complete them successfully.
Our specialists have built up and developed the necessary know-how in various automation projects from conceptual design to implementation. We support our customers to elicit the prerequisites for automation in a review.
Automation
Due to the agile approaches in many IT areas and in order to meet the resulting shorter provisioning times of IT infrastructure, many IT organisations are thinking about what could be automated with reasonable effort in order to meet the growing requirements on the part of the business.
In addition to agility, it is also the costs and not least the required quality that encourage automation. Once a process has been automated, IT staff with other qualifications or, in the best case, the customer of a service himself, can also carry out this step, which ultimately has a positive effect on costs.
Conditions
In order to automate a process, it must be standardised, i.e. it must always run in the same way with as few exceptions as possible. In addition, this process must be requested and carried out frequently in order to justify the effort of automation.
Automation also requires that the IT infrastructure is virtualised in the areas of compute, storage and network. If hardware has to be purchased and installed every time an additional instance of a service is to be switched on in the data centre, automation is not possible.
Type of automation
A distinction is made between vertical and horizontal automation. This graphic shows the difference.
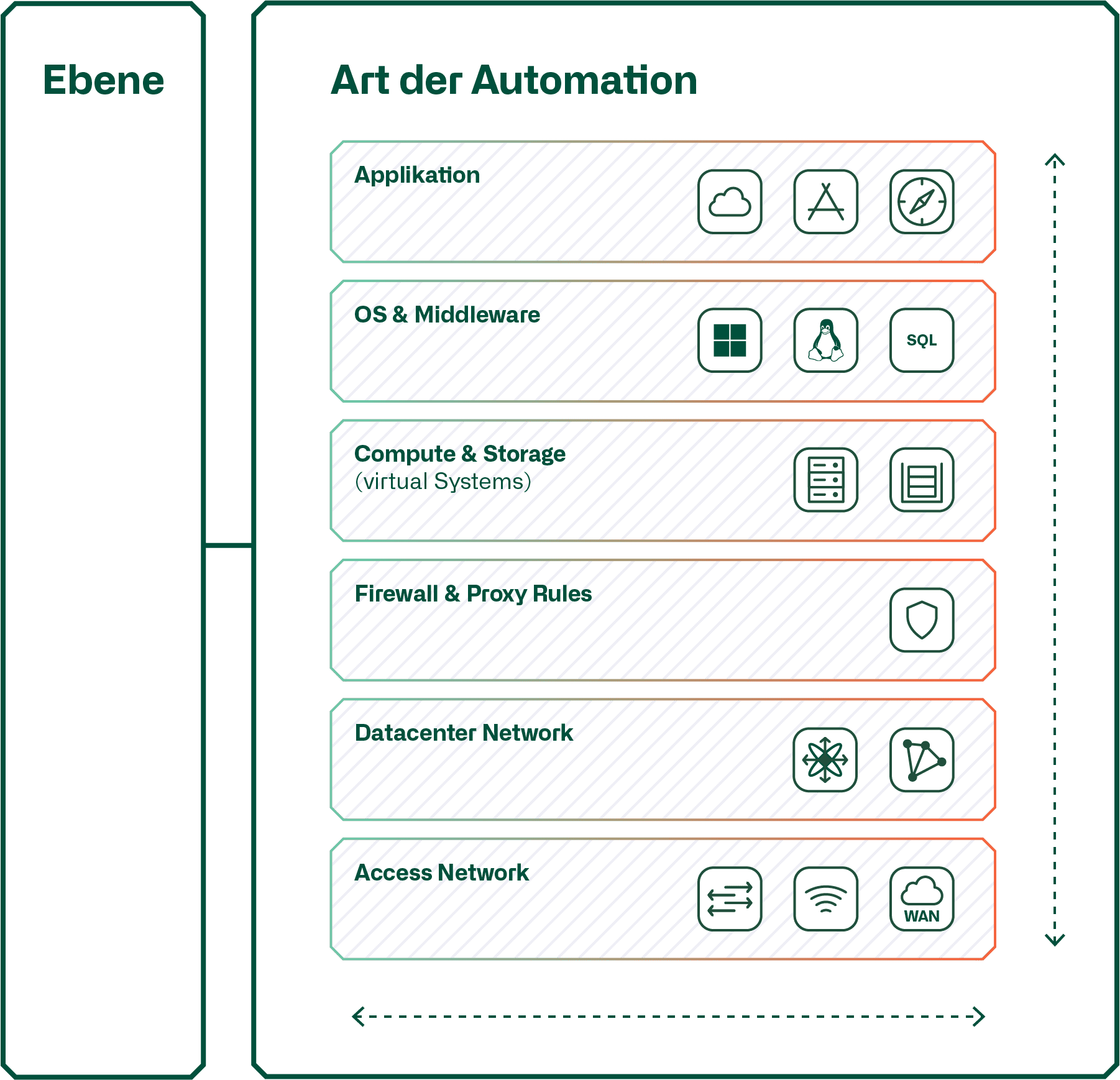
With horizontal automation, the processes are automated limited to the respective level. Here, as an example, the data centre network, which is automated with an "out of the box" SDN solution from a network manufacturer. Or the "Firewall & Proxy Rules" level is automated with a firewall policy management. The same applies to the "Compute & Storage" level, which is automated with the automation tools of the delivery agents of the virtualisation of compute or storage.
Only when the individual levels are sufficiently automated can vertical automation be realised in order to automatically provision instances of a multilayer service, i.e. a service that consists of services from different levels. In the case of vertical automation, this is often referred to as orchestration. Vertical automation requires that the products used to automate a layer have a "Northbound API". This is used by the vertical automation orchestrator to provision instances in the corresponding level. For example, to configure a virtual router with the associated VLANs on the "Datacenter Network" level, to which the orchestrator connects the VMs via the compute automation tool in a further step.
Architecture Automation Tools
The automation tools of one level all have approximately the same architecture. This is shown in the following graphic.
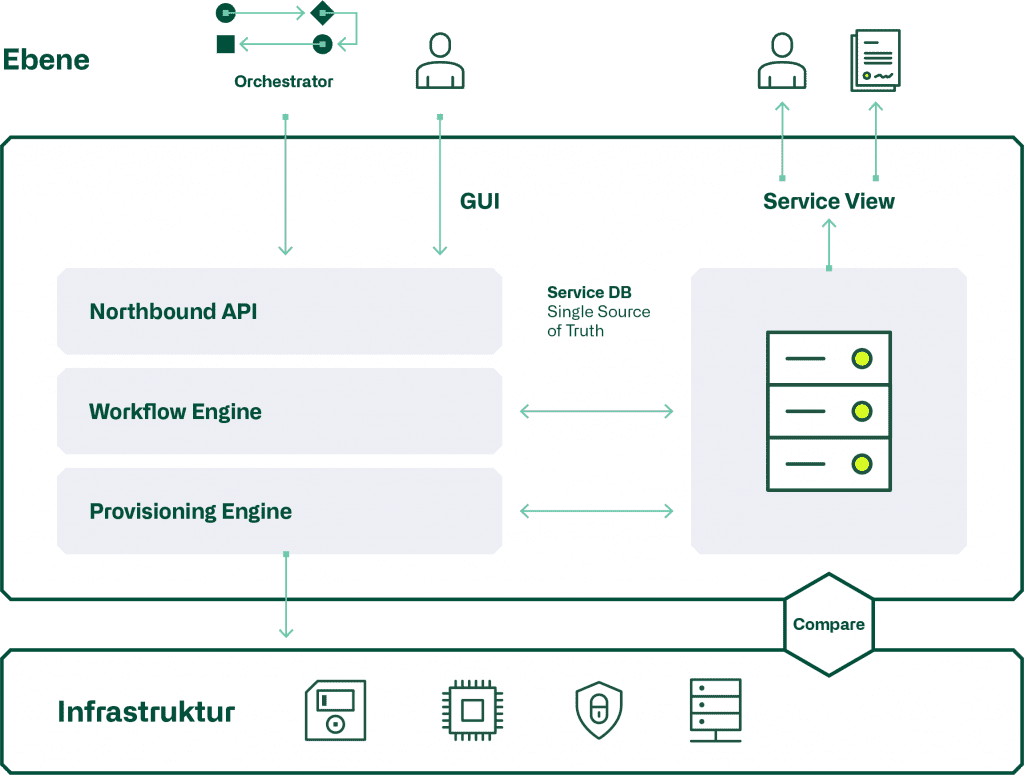
Let's start with the Northbound API, which is used to configure the services of a layer. This is done either through the GUI by a person, or directly by the vertical automation orchestrator. It is crucial here that the GUI also uses the "Northbound API", as this ensures that all GUI functions are also available to the orchestrator.
The Workflow Engine performs the various steps that make up the service. Subsequently, the "Provisioning Engine" creates the "Snipplets" necessary for configuration, which are then provisioned to the components of the infrastructure via Rest-API, Netconf or CLI. The structure and parameters of a service are recorded in the service DB, which always represents the "single source of truth".
In a model-driven automation, the configurations of the infrastructure components are periodically compared with the service database. This raises the question of how to deal with deviations. Often, only a report is created and the differences have to be corrected manually, since a direct reprovisioning from the service DB could result in an interruption of the affected service.
In addition, the service structure and parameters can be displayed directly online or as a report from the service database using the "Service Viewer" in the form of a service tree. This is an important feedback tool to check the correct functioning of the workflow and provisioning engine.