Neuer Senior Consultant bei atrete
Dominick Lusti wird neuer Senior Consultant im Bereich Cloud, Connectivity & Datacenter
Seit dem 1. Mai 2024 verstärkt Dominick Lusti unser Team als Senior Consultant im Bereich Cloud, Connectivity & Datacenter. Herr Lusti bereichert uns mit seiner umfangreichen Erfahrung als Teamleiter für Technik und interne ICT sowie als Systemtechniker. In seiner vorherigen Position war er verantwortlich für die Führung der Abteilung Technik, die Konzeption und Umsetzung kundenspezifischer IT- und OT-Infrastrukturen sowie die Erarbeitung und Prüfung von Sicherheits- und Lösungskonzepten. Er verfügt über einen Bachelor und Master of Science FHO in Wirtschaftsinformatik sowie über die Zertifizierung als Azure Solution Architect Expert.

Medienkontakt:
at rete ag
Marlene Haberer
Telefon: +41 44 266 55 83
Email: marlene.haberer@atrete.ch
Vorteile und Herausforderungen von Cloud-Management-Plattformen
Die Cloud Journey vieler Unternehmen hat längst begonnen und ein Grossteil von IT-Infrastrukturen und Lösungen werden erfolgreich in Cloud-Umgebungen betrieben. Mit diesem Trend stehen Unternehmen vor der Herausforderung, bereits eine Hybrid-Cloud- oder Multi-Cloud-Umgebung zu betreiben, die Lösungen verschiedener Anbieter umfasst. Dieser Ansatz nach dem Motto „Best of Breed“ ermöglicht es, die individuellen Stärken der Anbieter optimal zu nutzen. Gleichzeitig bringt es die Schwierigkeit mit sich, dass IT-Teams unterschiedliche Cloud-Umgebungen verwalten, anpassen und weiterentwickeln müssen, ohne dabei den Kostenfokus aus den Augen zu verlieren und geforderte Richtlinien einzuhalten. Um diese Aufgabe zu meistern, werden sogenannte Cloud-Management-Plattformen (CMPs) eingesetzt. Diese Tools ermöglichen Unternehmen, Multi-Cloud- und On-Premise-Umgebungen zentral mit einer Plattform zu verwalten.
In diesem Blog zeigen wir Ihnen, welche Aspekte eine Cloud-Management-Plattform abdeckt, wo wir die Grenzen solcher Tools sehen und worauf Sie bei der Auswahl einer geeigneten Lösung achten sollten.
Was ist eine Cloud-Management-Plattform?
Zentrales Management als Hauptmerkmal
Eine Cloud-Management-Plattform kann als multifunktionales Tool betrachtet werden, das eine zentrale Verwaltung unterschiedlicher Cloud-Anbieter, sowie On-Premises-Lösungen ermöglicht. Die Hauptdisziplinen bestehen insbesondere im Verwalten und Optimieren von Multi-Cloud- und Hybrid-Cloud-Umgebungen über eine zentrale Schnittstelle. Dabei soll die Plattform möglichst benutzerfreundlich und intuitiv sein, sodass die Benutzer über die grafische Oberfläche ihre Workloads verwalten können. Eine moderne und für die Zukunft gerichtete CMP unterstützt die Multi-Cloud-Fähigkeit und Integration von On-Premises-Ressourcen.
Erfahren Sie mehr über Multi-Cloud-Szenarien und warum Unternehmen bewusst oder unbewusst vor dieser Herausforderung stehen, in folgendem Blogbeitrag:
Multicloud – Macht das wirklich Sinn?
Die Funktionalitäten von Cloud-Management-Plattformen entwickeln sich ständig weiter und die Tools werden immer umfangreicher. Dabei lässt sich ein Trend erkennen, dass grössere Public-Cloud-Anbieter wie Microsoft Azure, Amazon Web Services (AWS) und Google Cloud Platform (GCP) ihre nativen Plattformen so erweitern, dass sie nicht nur auf ihre eigenen Dienste und Infrastrukturen fokussiert sind, sondern auch APIs und Tools zur Integration mit anderen Plattformen und Diensten bieten.
Einige Anbieter konzentrieren sich stärker auf einzelne Themenbereiche, und bieten somit spezifische Funktionalitäten an. Diese auch als «Minisuites» bezeichneten Lösungen betrachten wir nicht als vollwertige CMPs. Im Gegensatz dazu verfolgen andere Anbieter einen ganzheitlichen Ansatz, mit welchem sie eine breite Funktionalität abdecken. Dies erreichen sie durch die Integrationen anderer Produkte und Hersteller. Lassen Sie uns in den nächsten Abschnitten die wesentlichen Bestandteile einer Cloud-Management-Plattform betrachten.
Bereitstellung und Orchestrierung: Mit einer CMP kann Ihr IT-Team möglichst effizient Workloads bereitstellen. Dies wird erreicht, indem wiederkehrende Aufgaben automatisiert werden. Manuelle Eingriffe sind möglichst zu minimieren, um den Zeitaufwand und mögliche Fehlerquellen zu reduzieren.
Service Enablement: Mit Service Enablement können Sie einen individuell an Ihre Bedürfnisse angepassten Servicekatalog erstellen. Dies ermöglicht Cloud-Nutzern, die benötigten IT-Ressourcen einfach und standardisiert zu bestellen. Die angeforderten Ressourcen werden dann automatisiert und konform zu internen Sicherheitsvorgaben bereitgestellt.
Monitoring und Überwachung: Damit Sie Ihre Hybrid- und Cloud-Ressourcen über ein Dashboard im Blick haben, sammeln CMPs Daten von allen Anbietern und konsolidieren diese für Sie. Dadurch wird ein umfassendes Monitoring und eine lückenlose Überwachung aller IT-Ressourcen gewährleistet. Diese Daten können Sie beispielsweise für ein Reporting weiterverwenden.
Inventarisierung und Kategorisierung: CMPs helfen Ihnen dabei, eine umfassende Übersicht und Kontrolle Ihrer Infrastruktur zu haben. Ressourcen werden automatisch entdeckt und verwaltet, Änderungen überwacht und Konfigurationen zentral verwaltet. Fehlende Tags werden erkannt und automatisch nach von Ihnen definierten Kriterien hinzugefügt.
Kostenkontrolle und Ressourcenoptimierung: Mit der Kostenkontrolle und Ressourcenoptimierung bieten CMPs detaillierte Einblicke in Ihre Ausgaben und ermöglichen es, ungenutzte Ressourcen zu identifizieren und somit unnötige Kosten zu eliminieren. Durch eine automatische Skalierung können CMPs Ihnen helfen, die Cloud-Kosten zu minimieren.
Cloud Migration, Backup und Disaster Recovery: Eine CMP unterstützt Sie dabei, Recovery- und Business-Continuity-Architekturen aufzubauen. Zusätzlich ermöglicht Ihnen die zentrale Plattform eine umfassende Backup-Kontrolle, wodurch Sie die Integrität Ihrer Daten sichern und vor Verlust schützen können.
Identität, Sicherheit und Compliance: Mit einer CMP haben Sie den Überblick zu sicherheitsrelevanten Themen über sämtliche Cloud-Plattformen. Dies beinhaltet beispielsweise die Zugangsüberwachung (IAM) aber auch Dashboards zur Sicherheitskonformität in Bezug auf Ihre Sicherheitsrichtlinien.
Die einzelnen Themenbereiche können Ihnen bei der Auswahl von Bewertungskriterien helfen, um eine erfolgreiche Evaluation einer CMP durchzuführen.

Differenzierung der Tools – was können CMP-Lösungen nicht?
Cloud-Management ist eine komplexe Domäne. Dies wird bereits beim Betrachten des Funktionsumfangs klar. Die verschiedenen Anbieter von CMP-Lösungen richten sich weiterhin aus und fokussieren sich teilweise auf einzelne oder verwandte Themenbereiche.
Ein bedeutender Aspekt, den CMPs möglicherweise nicht vollständig abdecken, ist die initiale Erstellung und Konfiguration von Cloud-Infrastrukturen. CMPs sind primär für den Betrieb und die Verwaltung bestehender Infrastrukturen konzipiert und weniger für das Engineering. Der Aufbau einer Infrastruktur erfolgt meist nicht mit einer CMP, sondern mit spezialisierten Tools wie Terraform oder den nativen Plattformen. CMPs kommen ergänzend dazu, um die Verwaltung und Optimierung der bestehenden Infrastruktur zu unterstützen. Eine CMP ist primär für das Operation-Team gedacht, das die laufenden Prozesse überwacht und verwaltet.
Zwar bieten viele CMPs Integrationen für Infrastructure-as-Code (IaC) Ansätze und ermöglichen die Nutzung bestehender Terraform- und Ansible-Skripte, jedoch bleibt die Erstellung und Konfiguration der Infrastruktur ausserhalb des Kernfunktionsumfangs. Es ist möglich, eine Infrastruktur direkt mit einer CMP aufzubauen, doch dies ist oft nicht sinnvoll, da CMPs eher für das Management konzipiert sind und nicht die tiefgehende Flexibilität und Kontrolle bieten, die für das Engineering notwendig sind.
Der Nutzen einer CMP hängt von der Art und Weise der Ressourcenbereitstellung ab. Erfahrene DevOps-Teams mit hoher IaC-Maturität arbeiten oft mit Code und nutzen weniger grafische Oberflächen, da textbasierte Konfigurationsdateien und Skripte effizient in ihre CI/CD-Pipelines integriert werden können.
Mehr über die Rolle von CI/CD im IaC-Ansatz erfahren Sie im Blogbeitrag:
CI/CD und IaC
Weiter sind CMPs womöglich nicht in der Lage, die spezifischen, proprietären Dienste aller Cloud-Anbieter vollständig zu unterstützen, was zu Einschränkungen in der Funktionalität führen kann. Dies liegt daran, dass sich Cloud-Plattformen ständig weiterentwickeln und somit neue Funktionalitäten laufend dazukommen, währenddem andere verschwinden.
Mögliche Varianten und Tools
CMPs unterscheiden sich hinsichtlich ihrer Betriebsart. Einige Anbieter bieten ihre Lösungen als Software-as-a-Service (SaaS) an, was eine schnelle Implementierung und einfache Wartung ermöglichen. Andere setzen auf Self-hosted Lösungen, die mehr Kontrolle und Anpassungsmöglichkeiten bieten, aber auch einen höheren Verwaltungsaufwand erfordern.
Folgend können Sie eine Liste einiger Anbieter von Cloud-Management-Plattformen finden, die Liste ist nicht abschliessend:
- BMC Cloud Lifecycle Management
- CloudBolt
- Flexera
- IBM Cloud Pak for Multicloud Management
- Morpheus Data
- Nutanix Cloud Manager
- Red Hat CloudForms
- Scalr
- VMware vRealize Suite
Wer braucht eine CMP und was ist die beste Lösung für Sie?
Eine Cloud-Management-Plattform ist für verschiedene Organisationen und Szenarien vorteilhaft. Nachfolgend erläutern wir mögliche Szenarien, und was der Vorteil von CMPs für den Anwendungsfall ist.
So profitieren Unternehmen mit einer Multi-Cloud-Strategie von der zentralen Verwaltung verschiedener Cloud-Anbieter über eine Benutzeroberfläche. Grosse Unternehmen und Konzerne nutzen CMPs zur zentralen Steuerung und Übersicht ihrer umfangreichen IT-Infrastrukturen sowie zur Skalierung und Verwaltung komplexer Umgebungen. Unternehmen die als IT-Dienstleister und Managed Service Provider (MSPs) agieren, nutzen CMPs, um die Cloud-Infrastrukturen mehrerer Kunden effizient von einem zentralen Dashboard aus zu verwalten und Prozesse zu automatisieren. Unternehmen, die strengen Regulierungen und Sicherheitsanforderungen unterstellt sind, nutzen CMPs, um gesetzliche Vorgaben und Branchenstandards über verschiedene Cloud-Umgebungen hinweg einzuhalten und Sicherheitsrichtlinien konsistent anzuwenden. Es gibt viele weitere Szenarien, in denen CMPs von Vorteil sein können. Diese sind nicht nur auf bestimmte Branchen beschränkt oder nur für Technologieunternehmen relevant.
Um die passende Lösung für Ihr Unternehmen zu finden, empfehlen wir Ihnen zu prüfen, warum Sie eine Hybrid-Cloud- oder Multi-Cloud-Umgebung verwenden. Dies hilft Ihnen herauszufinden, welche Funktionen Ihre zukünftige Lösung primär abdecken soll. Ausserdem sollten Sie entscheiden, welche Tools komplementär zum Einsatz kommen und welche Tools Sie ablösen möchten.
Fazit
Der Einsatz einer CMP-Lösung macht besonders dann Sinn, wenn Sie eine Multi-Cloud-Strategie verfolgen, eine hohe Komplexität in Ihrer IT-Infrastruktur aufweisen, oder nach Möglichkeiten suchen, die Verwaltung zu automatisieren und die Effizienz zu steigern. Eine CMP-Lösung kann helfen, die Herausforderungen der Cloud-Verwaltung zu meistern, Kosten zu kontrollieren und sicherzustellen, dass alle Sicherheits- und Compliance-Anforderungen erfüllt werden.
Auch wenn viele Anbieter eine Kostenoptimierung anpreisen, können die Implementierung und der Betrieb kostspielig sein, da zusätzliche Lizenz- und Betriebskosten anfallen. Mitarbeitende müssen auf die neue Lösung geschult werden, bevor eine Effizienz spürbar wird. Der Aufwand für die Einrichtung ist nicht zu unterschätzen. Ob und welche CMP die beste Lösung ist, muss individuell betrachtet werden. Es gibt keine universelle Lösung oder einen De-Facto-Standard. Die beste Wahl hängt von Ihrer individuellen Ausgangslage, gepaart mit den Bedürfnissen und strategischen Zielen Ihres Unternehmens ab.
Möchten Sie mehr über die Vorteile und Implementierungsmöglichkeiten von Cloud-Management-Plattformen für Ihren Anwendungsfall erfahren? Kontaktieren Sie uns, und wir helfen Ihnen, die optimale Lösung für Ihre Bedürfnisse zu identifizieren – Gemeinsam finden wir die passende Lösung.
Die Zukunft der Netzwerke
Die digitale Ära hat den Stellenwert von Netzwerken in unserer täglichen Kommunikation und Interaktion erhöht. Im Bemühen, den steigenden Anforderungen an Sicherheit, Zuverlässigkeit und Effizienz gerecht zu werden, zeichnet sich das SCION-Netzwerkprotokoll als eine vielversprechende Lösung im Bereich der Weitverkehrskommunikation (Internet) ab. In diesem Blogbeitrag werden wir einen genaueren Blick auf SCION werfen und verstehen, wie es die bestehenden Paradigmen herausfordert.
Hintergrund: Was ist SCION?
SCION, was für „Scalability, Control, and Isolation On Next-Generation Networks“ steht, ist ein fortschrittliches Netzwerkprotokoll, das darauf abzielt, die Mängel traditioneller Internetarchitekturen zu überwinden. Entwickelt von Forschern der Eidgenössischen Technischen Hochschule Zürich (ETH Zürich), bietet SCION eine innovative Lösung für Herausforderungen wie Sicherheit, Skalierbarkeit und Effizienz.
Die Funktionsweise von SCION basiert auf einem Netzwerk aus vertrauenswürdigen Teilnehmern und wird über bestehende autonome Systeme (AS) in unabhängigen Routing-Ebenen, sogenannten Isolation Domains (ISD), organisiert. Jedes AS benötigt ein entsprechendes Zertifikat, um in eine ISD eingebunden zu werden. SCION bietet inhärente Sicherheit, da der Zugriff auf ein Kommunikationsnetzwerk immer explizit geregelt ist und Richtlinien durchgesetzt werden. Der SCION-Datenverkehr wird entlang von vordefinierten Pfaden geroutet, was den Nutzern effektive Kontrolle über den Weg ihrer Daten gibt. Durch den Multi-Path-Ansatz ist dies auch bei Ausfall eines Pfades zuverlässig, ohne Kompromisse bei den Wegvorgaben sichergestellt.
Sicherheit als oberste Priorität
Eine herausragende Eigenschaft von SCION ist seine intensive Ausrichtung auf Sicherheit. Im traditionellen Internet sind Bedrohungen wie DDoS-Angriffe und Manipulationen des Routings allgegenwärtig. SCION begegnet diesen Gefahren durch die strikte Trennung von Kontroll- und Datenübertragungsebenen. Dieses Konzept isoliert Angriffe auf die Kontrollschicht, was die Gesamtwiderstandsfähigkeit des Netzwerks erheblich stärkt.
Vertrauenswürdige Pfade und verbesserte Skalierbarkeit
SCION führt das Konzept der „vertrauenswürdigen Pfade“ ein, die auf vordefinierten Routen basieren. Im Gegensatz zum herkömmlichen Internet, in dem Pakete oft auf unvorhersehbaren Wegen durch das Netzwerk reisen, ermöglichen vertrauenswürdige Pfade eine präzise Kontrolle über den Datenverkehr. Dies verbessert nicht nur die Sicherheit, sondern auch die Effizienz und Skalierbarkeit des Netzwerks, da Engpässe vermieden und Latenzen reduziert werden.
Dezentralisierung der Kontrolle: Ein Paradigmenwechsel
Ein weiterer revolutionärer Aspekt von SCION ist die Dezentralisierung der Netzwerksteuerung. Im traditionellen Internet erfolgt die Kontrolle über Routing und Sicherheit zentralisiert durch Internet Service Provider (ISP) und Router. SCION hingegen ermöglicht eine autonome Kontrolle auf Netzwerkebene, was eine höhere Flexibilität und Anpassungsfähigkeit erlaubt. Diese Dezentralisierung verspricht nicht nur eine bessere Widerstandsfähigkeit gegenüber Angriffen, sondern fördert auch die Innovation in der Netzwerkgestaltung.
Ausblick auf die Zukunft
Mit der ständig wachsenden Bedrohung durch Cyberangriffe und der steigenden Komplexität unserer digitalen Welt ist die Entwicklung von Netzwerklösungen wie SCION von entscheidender Bedeutung. Die Kombination aus Sicherheit, Skalierbarkeit und Dezentralisierung positioniert SCION als vielversprechenden Kandidaten für die Netzwerkarchitektur der Zukunft. Während die breite Implementierung von SCION noch in den Kinderschuhen steckt, deuten die ersten Lösungen wie das von der Schweizerischen Nationalbank (SNB) und SIX initiierte Secure Swiss Finance Network (SSFN) darauf hin, dass wir Zeugen eines Paradigmenwechsels in der Welt der Netzwerke werden könnten.
Unsere Consultants werden den Paradigmenwechsel in der Welt der Netzwerke weiterhin verfolgen und unterstützen unsere Kunden, um ihre Netzwerkprojekte ganzheitlich erfolgreich durchzuführen.
Cloud Network Segmentation
Mit der Möglichkeit, Platform as a Service (PaaS) Dienste in ein virtuelles Netzwerk zu integrieren, steigert sich auch die Wichtigkeit eines sicheren, skalierbaren und effizient betreibbaren Netzwerkdesigns. Mit diesem Blog zeigen wir Varianten auf, wie Cloud Network Segmentation im Enterprise-Umfeld aussehen kann.
Grundsätze zur Cloud Network Segmentation
Eine Hub&Spoke-Netzwerk-Architektur hat sich in der Cloud als Best Practice etabliert und wird mittlerweile in den meisten Unternehmen im Enterprise-Bereich eingesetzt. Dabei werden übergreifende Netzwerkservices wie Firewall, Connectivity oder Routing zentral in einem Hub-Netzwerk gesteuert. Mittels Peerings werden Workload-Netzwerke (Spokes) mit dem Hub verbunden, wodurch sämtlicher Verkehr zwischen verschiedenen Spokes im Hub kontrolliert wird.
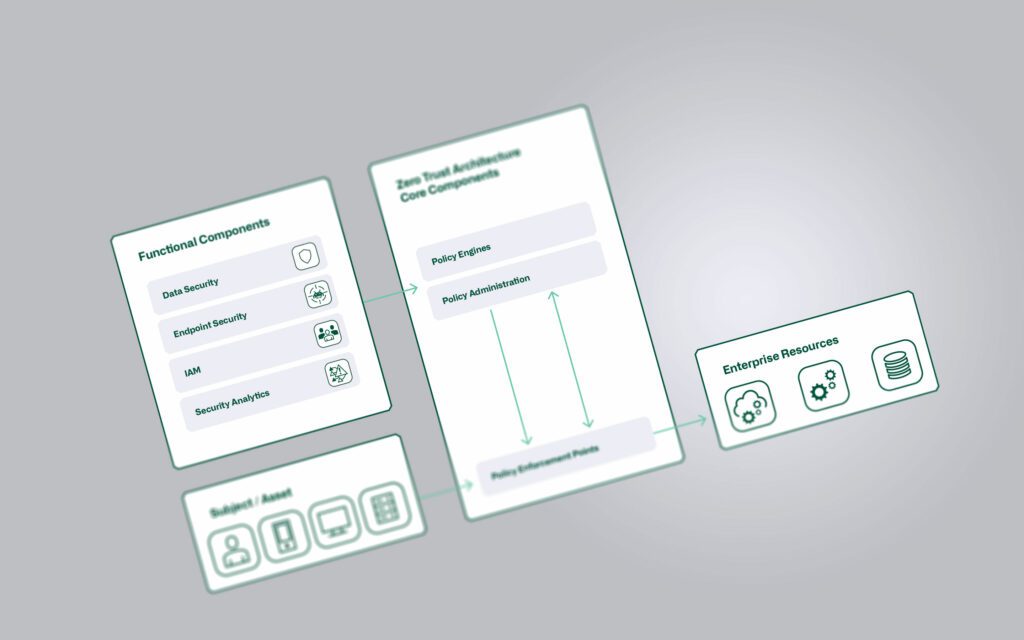
Während sich OnPremise der Weg zur Micro Segmentation als sehr aufwändig gestaltet, kommt dieses Konzept in der Cloud bereits standardmässig zur Anwendung. Dabei wird vermehrt ein Zero Trust Ansatz verfolgt, der eine deutlich striktere Abschottung von einzelnen Applikationen ermöglicht. Dies widerspiegelt sich auch in Controls von diversen Best Practice Security Frameworks wie dem Microsoft Cloud Security Benchmark (NS-1/NS-2), CIS Controls (3.12, 13.4, 4.4), NIST SP 800-53 (AC-4, SC-2, SC-7) oder PCI-DSS (1.1, 1.2, 1.3).
Blog
Ergänzende Informationen zu Zero Trust finden Sie in unserem dedizierten Blog-Beitrag:
Implementierung einer Zero Trust Architektur
In der Cloud existieren dabei fünf grundlegende Werkzeuge, die zu einer funktionierenden Network Segmentation beitragen:
- Virtuelle Netzwerke
Mit Hilfe von VNets (Azure) oder VPCs (AWS und Google) lassen sich Ressourcen isolieren, da eine freie Kommunikation standardmässig nur innerhalb eines virtuellen Netzwerks möglich ist. Mittels Peerings zum Hub können diese jedoch miteinander verbunden werden.
- Subnetze
Innerhalb eines virtuellen Netzwerks ist eine zusätzliche Segmentierung durch Subnetze möglich. Dadurch können einzelne Applikationskomponenten (z.B. Frontends, Key Vaults oder Datenbanken) voneinander isoliert und von der Firewall über die spezifischen Subnetz-Ranges angesteuert werden.
- Firewalls
Mit Firewalls lässt sich Traffic steuern und inspizieren, der über Peerings zum Hub geschleust wird. Dies erfolgt auf definierten IP-Adressen oder -Adressbereichen (L3), kann aber auch mittels FQDN-Regeln auf einem erhöhten Layer (L7) implementiert werden.
- Network Security Groups / Network Access Control Lists / VPC Firewall Rules
Network Security Groups (NSGs, Azure), Network Access Control Lists (ACLs, AWS) oder VPC Firewall Rules (GCP) sind vereinfachte Firewalls, die den Verkehr innerhalb eines virtuellen Netzwerks regeln. Diese NSGs bzw. ACLs werden dabei an einzelne Subnetze angehängt und definieren dort den eingehenden und ausgehenden Verkehr auf Basis Source / Destination, Protokoll und Port.
- Route Tables
Standardmässig wird ausgehender Internetverkehr direkt aus dem jeweiligen Subnetz ins Internet geroutet. Um dies zu ändern und den Verkehr zunächst in einer Firewall zu inspizieren bzw. zu steuern, können Route Tables und User Defined Routes (UDRs) eingesetzt und mit Subnetzen verknüpft werden.
Nun stellt sich allerdings die Frage, wie die zuvor genannten Werkzeuge bestmöglich miteinander kombiniert werden können, um das Ziel einer effizienten, sicheren und skalierbaren Segmentierung zu erreichen.
Für eine bessere Leserlichkeit werden in den nachfolgenden Abschnitten die Terminologien von Microsoft Azure verwendet, das Prinzip gilt allerdings jeweils genauso für AWS und GCP.
Variante 1 – Segmentierung virtueller Netzwerke
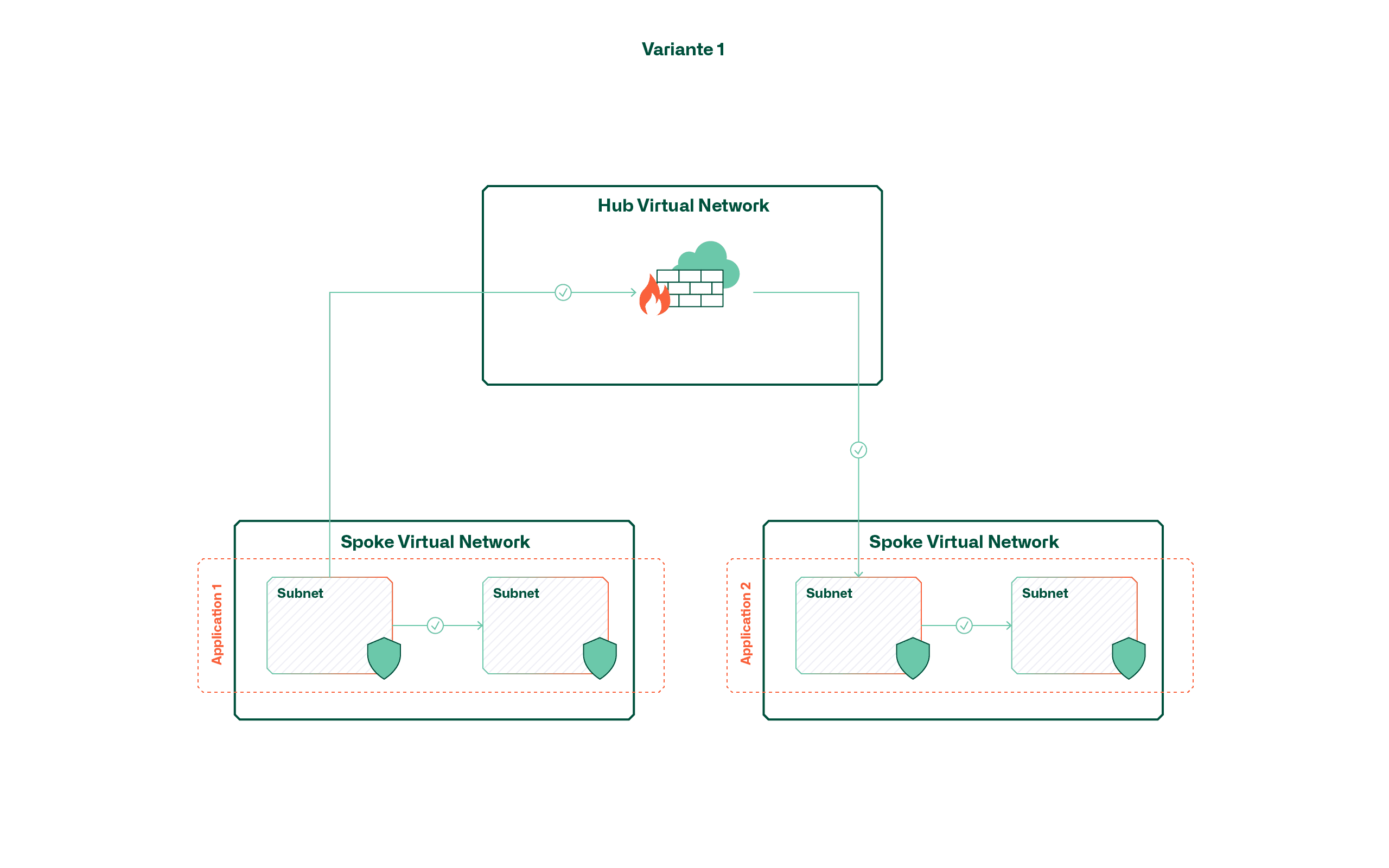
Diese Variante verfolgt den Grundsatz, dass jede Applikation bzw. jeder Service in einem dedizierten virtuellen Netzwerk gehostet wird. Dabei wird erreicht, dass standardmässig eine virtuelle Hülle um die Applikation entsteht und die Kommunikation innerhalb über Subnetze und Network Security Groups gehandhabt wird.
Der Vorteil dieser Variante liegt vor allem in der niedrigen Komplexität und der durchgehenden Isolation von Applikationen, da die Applikationsgrenzen direkt mittels virtueller Netzwerke erzwungen werden. Allerdings gilt es zu beachten, dass aufgrund der limitierten Anzahl Peerings (bei Azure sind es derzeit 500 pro Hub) die maximale Anzahl an Applikationen entsprechend begrenzt ist. Diese Limitation fällt noch mehr ins Gewicht, wenn pro Applikation getrennte Umgebungen (Dev, Test, Prod) erforderlich sind.
Ein weiterer Faktor, den es bei dieser Variante zu berücksichtigen gilt, sind die Kosten. Die Anzahl an VNets ist zwar kein direkter Kostenfaktor, allerdings wird sämtlicher VNet-übergreifender Verkehr verrechnet. Eine Überlegung kann daher sein, dass Applikationen, die häufig und viel Daten austauschen, im selben VNet geclustert werden.
Variante 2 – Segmentierung mittels Subnetze
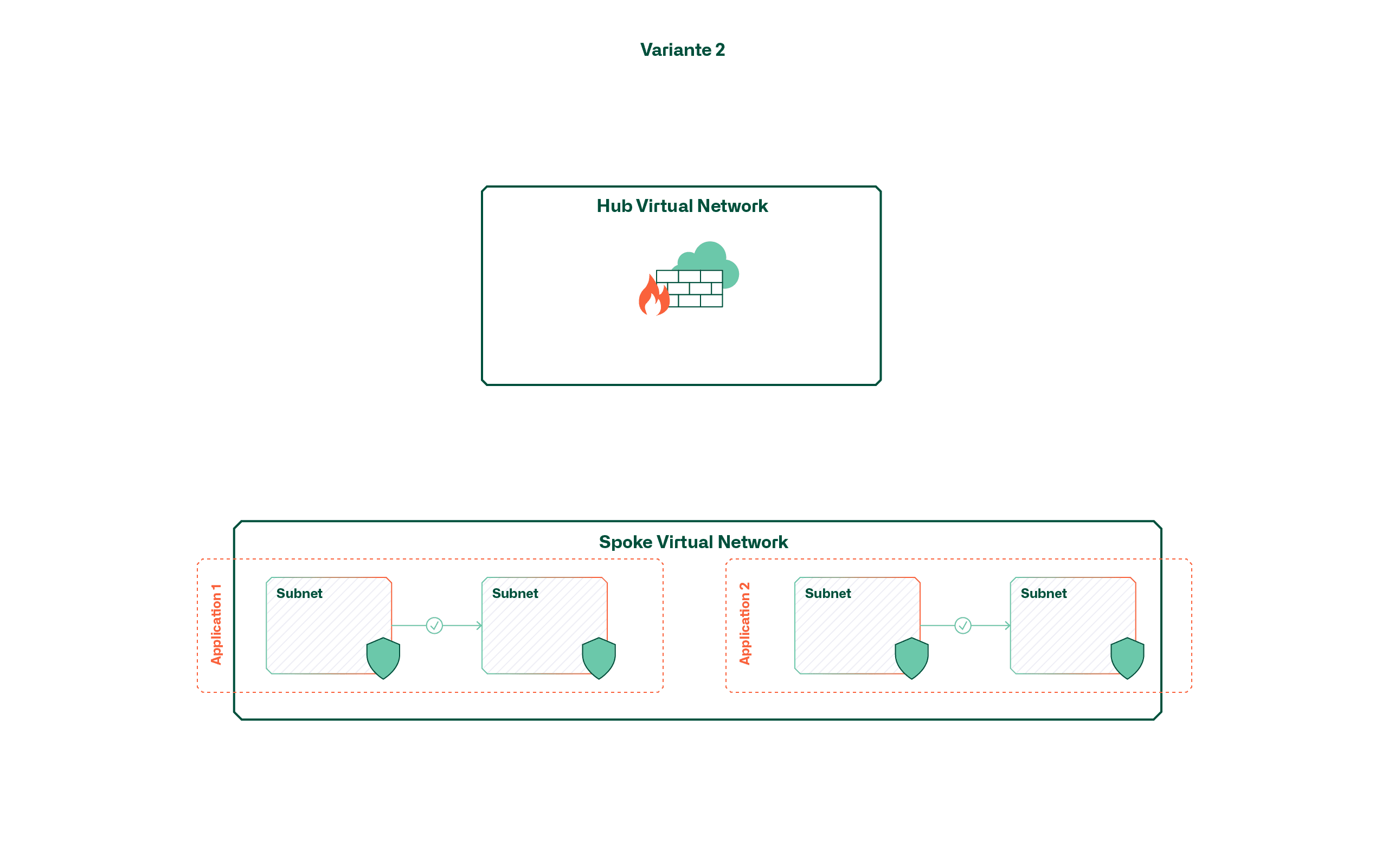
Anstelle von applikationsspezifischen virtuellen Netzwerken werden bei dieser Variante grössere, geteilte Netzwerke (z.B. pro Umgebung) eingesetzt. Die Abgrenzung von Applikationen innerhalb dieser virtuellen Netzwerke erfolgt dabei (wenn überhaupt erwünscht) über Subnetze und Network Security Groups. Dies bedeutet somit, dass hier standardmässig eine offene Kommunikation innerhalb einer Umgebung respektive Zone möglich ist.
Diese Variante bringt wiederum den Vorteil der einfachen Handhabung mit, sofern ein offener, applikationsübergreifender Verkehr erwünscht ist. Ist dies nicht der Fall, führt dies mit einer steigenden Anzahl Applikationen zu einer unübersichtlichen Landschaft an Subnetzen und Network Security Groups. Vor allem die Tatsache, dass aktuell keine übergreifende Ansicht zum Management von Subnetzen oder NSGs existiert, erschwert das Verwalten von Regeln bei zusätzlichen Applikationen.
Variante 3 – Segmentierung mittels Route Tables und Firewall
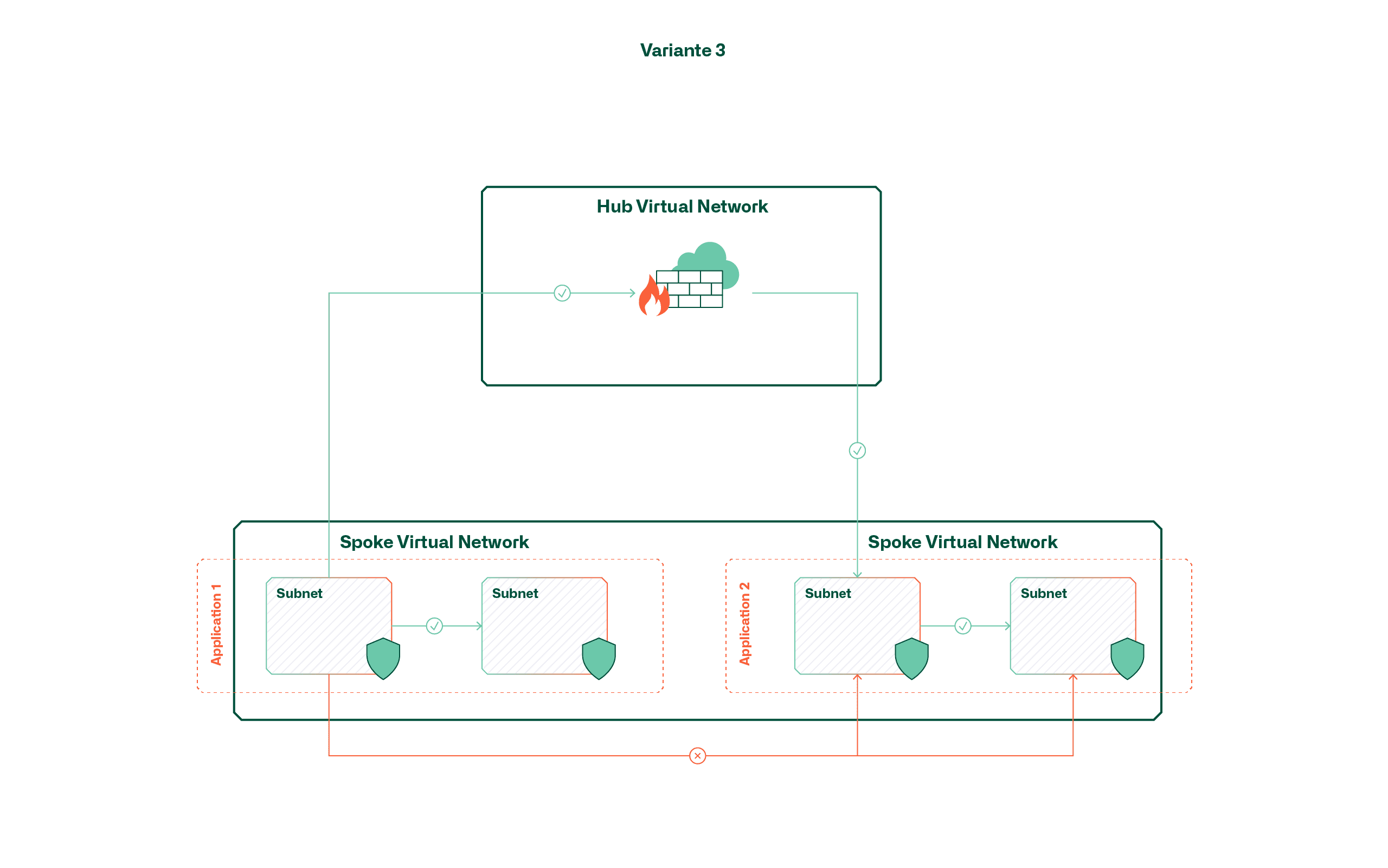
Bei dieser Variante wird ein Mix zwischen den ersten beiden Varianten erzielt, indem Applikationen zwar in einem grossen, geteilten Netzwerk platziert werden, der Verkehr aber stets zur zentralen Firewall im Hub geroutet und dort gesteuert wird. Dies wird mit mehreren User-defined-Routes (UDRs) ermöglicht, die die standardmässig vorhandenen Routen innerhalb des virtuellen Netzwerks übersteuern.
Zwar könnte bei dieser Variante der Eindruck entstehen, dass die Vorteile der zuvor erwähnten Varianten kombiniert werden können, allerdings wird bei steigender Applikationsmenge auch hier die Handhabung komplex. Der Grund dafür liegt darin, dass die Standardrouten nur durch UDRs übersteuert werden können, wenn diese gleich spezifisch oder spezifischer sind. Eine Default-Route (0.0.0.0/0) bringt in diesem Fall für internen Verkehr nicht den gewünschten Effekt, vielmehr müsste für jedes Subnetz auch eine zusätzliche Route erstellt werden (max. 400 pro Route Table).
Fazit / Empfehlung
Um dem Zero Trust Ansatz gerecht zu werden, empfehlen wir Variante 1 und somit eine strikte netzwerktechnische Trennung von Applikationen mit Hilfe von dedizierten virtuellen Netzwerken. Microsoft hat diesen Ansatz indirekt auch in ihrem Cloud Adoption Framework verankert und sieht vor, dass Applikationen prinzipiell in dedizierten Subscriptions platziert werden (Subscription Democratization), was folglich auch zu dedizierten virtuellen Netzwerken führt.
Der Grund für diese Empfehlung liegt hauptsächlich in der mittelfristig notwendigen Skalierbarkeit. Zwar mag zu Beginn mit einem überschaubaren Cloud-Portfolio ein geteiltes virtuelles Netzwerk sinnvoll erscheinen, mit der zunehmenden Anzahl Applikationen steigen der Betriebsaufwand und die Komplexität allerdings exponentiell. Ein Architekturwechsel ist zwar auch im Nachhinein möglich, bedeutet aber ein Neu-Deployment sämtlicher Komponenten innerhalb des virtuellen Netzwerks.
Grundsätzlich empfehlen wir das Netzwerkdesign in einem Cloud-Vorhaben nicht zu unterschätzen und sich bereits zu Beginn damit auseinanderzusetzen. Schliesslich gilt das Netzwerk, zusammen mit Identity Management und Governance-Mechanismen (Policies, RBAC, etc.), als einer der Grundpfeiler, auf dem die Applikationen aufsetzen.
Die atrete IT consultants sind Ihre Anlaufstelle für spezialisierte Cloud-Lösungen. In einer Zeit, in der sich die Technologielandschaft ständig verändert, haben wir unsere über 25-jährige IT-Infrastruktur Kompetenz in den Bereichen Cloud Netzwerk, Cloud Security, Cloud Automation und Cloud Strategie gebündelt. So entwickeln wir massgeschneiderte Lösungen für Ihre Herausforderungen.
Cloud Servicemodelle – welche Skills werden in welcher Ausprägung benötigt?
Die Transformation einer Applikation zu einem Cloud-Provider setzt nicht nur neues Know-how voraus, sondern erfordert auch immer zusätzliche Ressourcen – eine Entlastung erfolgt erst nach konsequentem Abbau bestehender Infrastrukturen.
Was bedeutet die Cloud Journey für die internen IT-Skills?
Cloud Computing oder kurz «die Cloud», wie dies heute umgangssprachlich bezeichnet wird, erlebt derzeit einen immensen Hype. Von allen Seiten werden grosse Versprechen gemacht, Erwartungen geschürt, jedoch auch Bedenken geäussert und zur Vorsicht gemahnt. Dies ist eine typische Situation, wie sie bei disruptiven Technologien immer wieder auftritt. Für IT-Verantwortliche bedeutet dies, dass sie sich zusammen mit ihren Business-Verantwortlichen mit den neuen Möglichkeiten, Risiken und Folgen auseinandersetzen und ihren eigenen Weg in die Cloud definieren müssen.
Eine Facette der Cloud Journey, welche vor allem zu Beginn unterschätzt wird und oft zu wenig Beachtung findet, ist die Frage: Welche Skills und welches Know-how benötigt ein Unternehmen, wenn es seine IT-Dienstleitungen hauptsächlich mit Cloud Computing Services produziert? Dabei gilt es, sich vom doch weit verbreiteten Marketing-Versprechen nicht blenden zu lassen, welches suggeriert, dass Cloud-Services ohne eigenes Dazutun einfach konsumierbar sind.
In der realen Welt sind IT-Applikationen in den seltensten Fällen isolierte Systeme, sondern fast immer ein Teil eines Verbundes mit Schnittstellen zu anderen Applikationen und Umsystemen. Aus Benutzersicht wird dabei eine möglichst einheitliche User-Experience erwartet. Die Integration der verschiedenen Applikationen zu einer sinnvollen IT-Landschaft ist für jedes Unternehmen speziell und für die jeweiligen Anforderungen individuell angepasst und optimiert.
Dabei umfasst die Palette der zum Einsatz kommenden Servicemodellen ein facettenreiches Angebot und kann grob in die folgenden allgemein bekannten Kategorien eingeteilt werden:
- Software as a Service (SaaS)
- Platform as a Service (PaaS)
- Infrastructure as a Service (IaaS)
- On Premises
Die Kunst besteht nun darin, aus allen zur Verfügung stehenden Möglichkeiten eine möglichst einheitliche, durchgängige und kostenoptimierte IT-Landschaft zu entwickeln und zu betreiben. Dabei ist, wie bereits erwähnt, dem Aspekt der je nach Servicemodelle benötigten Skills und Know-how die erforderliche Aufmerksamkeit zu schenken.
Know-how, Skills und Servicemodelle
Je nach Servicemodell verschieben sich die benötigten Skills von hoch-technischen hin zu mehr serviceorientiertem organisatorischem Know-how. Nebst der Verschiebung der Skills ist jedoch auch der Aufwand für die Ausführung der Tätigkeiten zu beachten. In der nachfolgenden Grafik haben wir relevante IT-Skills den verschiedenen Servicemodellen gegenübergestellt. Die Bewertung basiert dabei auf der benötigten Wissenstiefe, der Komplexität der Zusammenhänge sowie der dafür aufzuwendenden Zeit und Ressourcen.

Betrieb
Inhouse benötigte Betriebs-Skills reduzieren sich linear mit der Reduzierung der Fertigungstiefe der Servicemodellen, da immer mehr Infrastrukturkomponenten zum Provider ausgelagert werden. Die regelmässige Wartung von Hardware, Betriebssystemen und Datenbanken fällt so mit steigendem Servicemodelle stufenweise weg.
Engineering
Betreffend Engineering zeichnet sich ein ähnliches Bild ab. Die Abstufung der benötigten Skills ist jedoch deutlich steiler als im Betrieb. Werden neue Services erstellt oder bestehende weiterentwickelt, ist der Aufwand bei PaaS oder IaaS Lösungen deutlich höher als bei SaaS, da hierbei auf deutlich mehr Schnittstellen und Kompatibilitäten beachtet werden müssen.
Architektur
Im Bereich der Architektur können interne Skills vorwiegend mit dem Einsatz von SaaS Diensten eingespart werden. Der konzeptionelle Aufwand, um IaaS oder PaaS Services in die IT-Landschaft zu integrieren ist dabei nur teilweise geringer als neue On-Prem Dienste zu konzipieren. Auch hier spielen wieder Themen wie die Kompatibilität und Schnittstellen zu vorhandenen Diensten eine grössere Rolle.
Security
Die Sicherheit in der IT-Landschaft ist in allen Servicemodellen gleich relevant. Der Fokus der Security verschiebt sich jedoch vertikal von technischen Skills wie z.B. der Härtung des Systems hin zu organisatorischen Aufwänden, wie die Prüfung von Datenstandorten. Interne Aufwände können somit nur durch den Bezug von SaaS Diensten reduziert werden, da hierbei jegliche Arbeiten betreffend der unterliegenden Infrastruktur vom Provider übernommen werden.
Identity
Im Bereich des Identitäten Managements steigen die Anforderungen an die intern benötigten Skills, wenn Dienste von On-Prem auf ein „as-a-Service“ Modell ausgelagert werden so lange, bis alle unterliegenden Infrastrukturkomponenten dem Provider überlassen werden. PaaS und IaaS bieten im Identity Management somit die Nachteile von on-Prem und SaaS, ohne deren Vorteile zu übernehmen. Es kommt ein zusätzliches Identity Management ins Spiel, welches in das bestehende System integriert oder ergänzend verwaltet werden muss. Neben dem Zugriff auf die Applikation müssen auch weiterhin Berechtigungen auf die darunterliegenden Infrastruktur Bestandteile gesetzt werden.
Datenhaltung
Das relevante Know-how für eine korrekte Datenhaltung unterscheidet sich stark je nach eingesetztem Servicemodell. Während bei einer SaaS Lösung im Vorfeld mehr Gedanken betreffend Datenstandort & Zugriff notwendig sind, benötigt es beim On-Prem Ansatz technischere Skills im Bereich Backup und Verfügbarkeit. IaaS und PaaS Service haben hierbei höhere Anforderungen, da das Know-how zu beiden Themenbereichen griffbereit sein muss.
Kostenmanagement
Ein Überblick über die Kosten benötigt es in allen Servicemodellen gleichermassen. Der Aufwand und das Wissen, welches für die Erstellung einer solchen Übersicht benötigt wird, unterscheidet sich jedoch wieder zwischen den Servicemodellen. PaaS und SaaS Services haben dabei besonders hohe Anforderungen. Dienste wie z.B. eine SQL-Datenbank können in verschiedenen Funktionsweisen, Verfügbarkeitsstufen, Skalierungsstufen und Grössen bezogen werden. Neben dieser technischen Diversität, können auch bei den Verrechnungsmodellen weitere Unterscheidungen gemacht werden. Die Betriebskosten können so schnell in eine unerwartete Höhe steigen und sind so je nach Konfiguration erst Ende Monat transparent ersichtlich. SaaS Dienste mit ihren User- oder Gerätelizenzen sind deutlich einfacher gestaltet. Da On-Prem nicht auf dem pay-as-you-go Prinzip basiert, ist es deutlich komplexer die Kosten von einzelnen Komponenten zu bestimmen. Bei Fehlern in der Kalkulation resultiert dies jedoch nicht in einer unerwartet hohen Rechnung.
Providermanagement
Providermanagement beinhaltet die Kunst, auf Änderungen eines bezogenen Services oder Applikation durch den Provider schnell reagieren zu können, um mögliche negative Auswirkungen zeitgerecht entgegenwirken zu können. Je mehr Kontrolle über die eigene Infrastruktur abgegeben wird, desto mehr Aufwand muss hierbei getätigt werden. In einem Worst-Case-Szenario ist z.B. eine Applikation auf einer IaaS VM deutlich schneller migriert als die gleiche Anwendung in einem SaaS-Modell. Backup, Disaster Recovery oder auch Verfügbarkeiten werden mit sinkender Fertigungstiefe vermehrt nur noch vertraglich und nicht über Konfigurationen des Engineers implementiert.
Fazit
Eine IT-Landschaft basiert unter dem Einfluss vom zunehmenden Einsatz von Cloud Computing auf eine immer grösser werdende Vielfalt an Servicemodellen. Grundsätzlich kann man davon ausgehen, dass die Breite des benötigten Know-how umso grösser wird, je unterschiedlicher die eingesetzten Servicemodelle sind.
Für die Beherrschung dieser verschiedenen Servicemodelle benötigt es somit nicht zwingend neue Skills, sondern oft Anpassungen des bereits vorhandenen Know-hows. Obwohl zum Beispiel der Betriebsaufwand mit der Migration von On-Premises in die Cloud tendenziell sinkt, sollte sich ein Unternehmen trotzdem mit neuen Themen wie z.B. IaC oder DevOps auseinandersetzen.
Blog
Ergänzende Informationen zu CI/CD und IaC finden Sie in unserem dedizierten Blog-Beitrag
CI/CD und IaC
Neu anfallende Aufgaben, welche durch eine Migration und den damit zusammenhängenden Änderungen im benötigten Know-how generiert werden, sind jedoch in allen Fällen als Zusatzaufwand zu verstehen. Dies ist so lange der Fall, bis die bestehende Umgebung aktiv zurückgebaut wird. Die Wahl des Servicemodells hat hierbei kein Einfluss.
Es gilt also in der Cloud-Strategie sorgfältig abzustimmen, welche Servicemodelle eingesetzt werden sollen, um daraus abzuleiten, in welcher Ausprägung die heute vorhandenen Skills in Zukunft benötigt werden. Jedes Unternehmen muss daher detailliert analysieren, welches Know-how neu aufgebaut, welches nicht mehr gepflegt und welches gegebenenfalls von aussen hinzugezogen werden soll.
atrete als unabhängige Beratungsfirma setzt sich laufend bei verschiedenen Kunden mit Problemstellungen rund um IT und Cloud auseinander. Wir können Unternehmen einerseits im Kontext ihrer Cloud Journey bei der Analyse und Definition der notwendigen Skills unterstützen. Andererseits stellen wir auch Fachkräfte mit spezifischen Skills für die externe Unterstützung der internen Teams zur Verfügung.
atrete erhält weitere Verstärkung
Im letzten Monat hat das IT Beratungsunternehmen atrete weitere Verstärkung erhalten. Unser neuer Kollege erweitert den Bereich Cloud.

Marco Jenny ist seit 01.09.2022 als Consultant in der Practice Area cloud bei atrete tätig. Er besitzt langjährige Berufserfahrung in der IT-Dienstleistung in den Bereichen System Engineering, Application Management und Cloud. Sein Fachhochschulabschluss als Wirtschaftsinformatiker FHNW zusammen mit einer Zertifizierung als Requirements Engineer (IREB Foundation) runden sein Profil ab.
Vor der atrete war Marco Jenny als Application System Engineer in der Microsoft Cloud mit starkem Fokus auf die Konzeption und Einführung von Modern Workplace tätig. Durch den technologischen Wandel in den vergangenen Jahren erhielt er dadurch Einblick und Erfahrungswerte in unterschiedliche Arten von Microsoft Cloud Projekten.
Ergänzend zu diesen Erfahrungen befindet sich Marco in der Weiterbildung zum «Microsoft Azure Solution Architect Expert»
Mikrosegmentierung: Wo stehen wir heute?
Was versteht man unter Mikrosegmentierung (Microsegmentation) ?
Mikrosegmentierung hat im Zuge der Virtualisierung von IT- und Netzwerk-Infrastrukturen im Datacenter, dem Wachstum durch die allgemeine Digitalisierung, und der damit verbundenen Dynamik seine Bedeutung bekommen. Unter dem Begriff Mikrosegmentierung werden Sicherheitstechnologien und -produkte verstanden, die eine feingranulare Zuordnung von Sicherheitsrichtlinien (Security Policies) zu einzelnen Servern, Applikationen und Workloads im Datacenter erlauben. Dies ermöglicht es, Sicherheitsmodelle und deren Anwendung tief innerhalb der Datacenter-Infrastrukturen und Topologien und nicht nur an grösseren Netzwerk- und Zonenperimetern anzuwenden. Dies hat grosse Bedeutung bekommen als in modernen digitalisierten Umgebungen ein Grossteil des Datenverkehrs zwischen Applikationen und Servern innerhalb des Datacenters erfolgt und nicht mehr hauptsächlich von aussen nach innen oder umgekehrt.
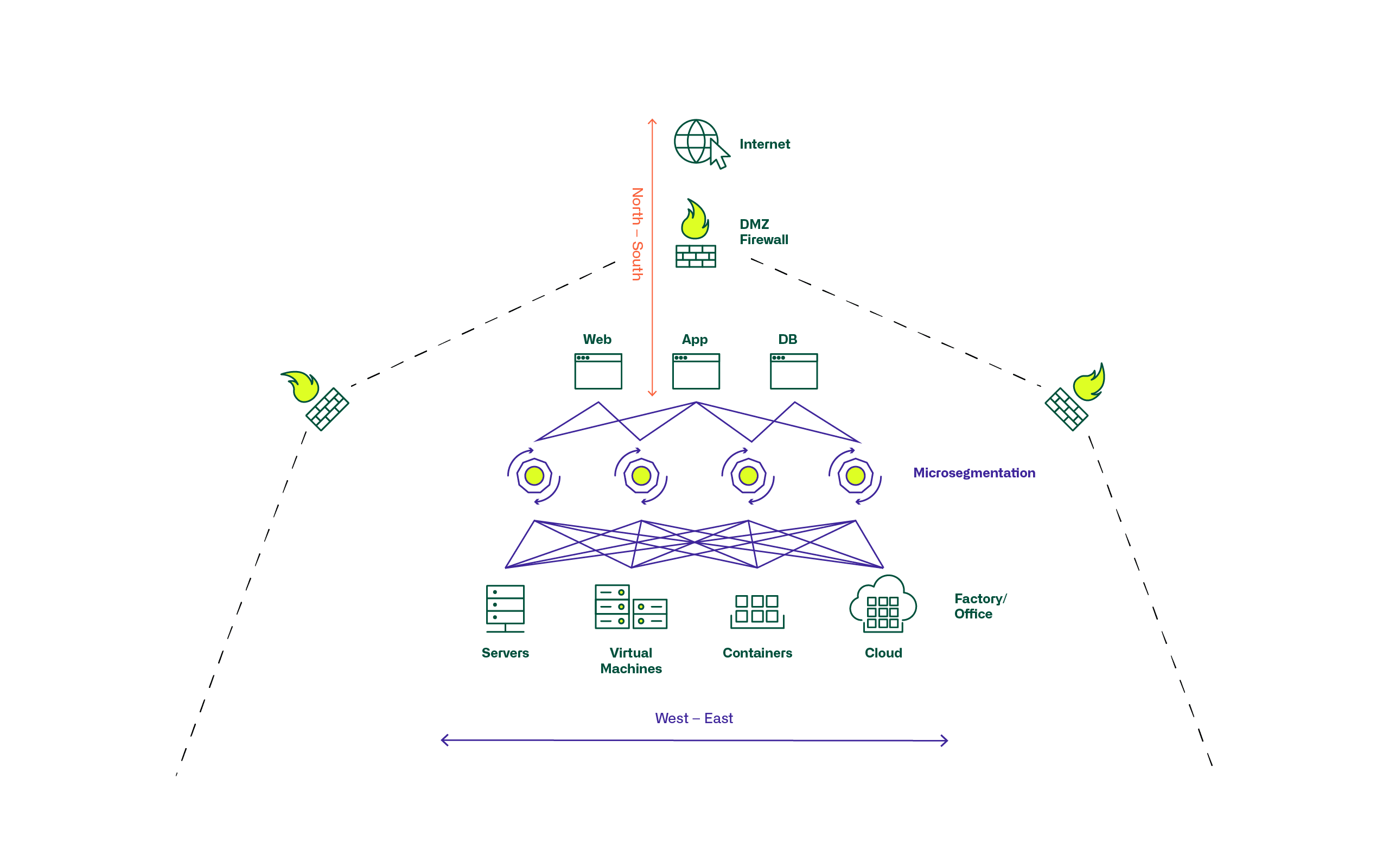
Mikrosegmentierung hat sich in unterschiedlichem Grad etabliert.
In klassischen Infrastrukturen werden mit vermehrter Netzwerk-Virtualisierung und Automatisierung kleinere Netzwerksegmente gebildet. Allgemein gültige Firewallregeln, angewendet auf ganze Zonen, werden abgelöst durch pin-holing mit individuellen Regeln je Server/Applikation.
Die Server- und Netzwerkinfrastruktur hat sich verändert von wenig flexiblem, individualisiertem und manuellem Perimeterschutz über teil-automatisierte Zonen, Typen und Klassen von Servern zu mikrosegmentierten, hoch strukturierten, standardisierten und dafür automatisierten Systemen.

Dies stellt auch andere Anforderungen an die Verwaltung und den Unterhalt der Security Policies und Firewallregelsets im Speziellen als an vielen Orten nicht die eine oder anderer Umgebung in Reinkultur existiert, sondern Übergänge und Schnittstellen von alten auf neue und software defined zu klassischer Infrastruktur betrieben und sichergestellt werden müssen.
Unter den verfügbaren Produkten und Technologien gilt es zu unterscheiden zwischen
- Netzwerk-basiert
- Hypervisor integriert oder Cloud-native
- Server OS/Workload integriert als eigene Applikation
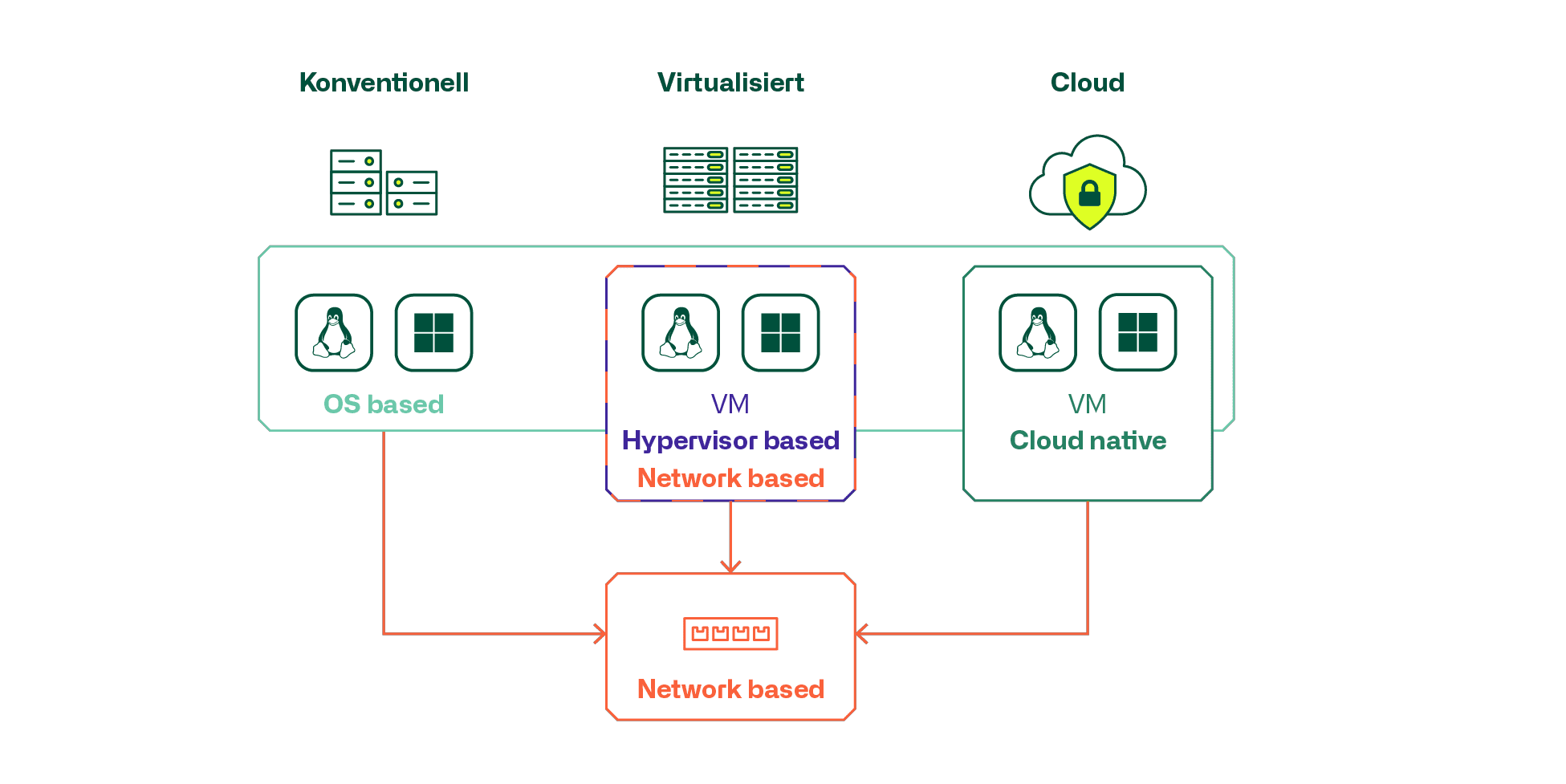
Dabei lassen sich die häufigsten Anwendungsfälle auch etwas gruppieren.
In konventionellen Serverinfrastrukturen wird primär mit Produkten mit netzwerk- oder OS-basierter Mikrosegmentierung gearbeitet. Dabei gilt es darauf zu achten inwiefern ältere Server und OS Versionen von OS basierten Produkten überhaupt unterstützt werden.
Für klassisch virtualisierte und private Cloud Infrastrukturen werden häufig die Hypervisor basierten, und in die Virtualisierung integrierte Mikrosegmentierungslösung verwendet und bei public Clouds die vom Cloud-Anbieter angebotene Cloud-native Lösung.
Vor allem in grösseren Umgebungen zeigt sich, dass häufig Kombinationen von Technologien und Produkten eingesetzt werden und Anforderungen an eine produktübergreifende Verwaltung und Administration von Security Policies und FW Regeln und Objekten gestellt werden. Diese Anforderungen steigen mit dem Grad der Virtualisierung, Mikrosegmentierung und hoch-dynamischen automatisierten Cloud- und Container-Infrastrukturen. Es wird zur Herausforderung, die dynamische und automatisierte Erstellung von Instanzen und Objekten, sowie deren Löschung in durchgängigen Konfigurationen automatisiert sicherzustellen. Die Entwickler von heute sind sich gewöhnt, ganze Applikationsumgebungen automatisiert zu erstellen und wieder zu löschen und die Infrastruktur muss Schritt halten damit die entsprechenden Security Policies und Regeln mit den effektiv vorhandenen Instanzierungen übereinstimmen.
Unsere Berater unterstützen Sie gerne, damit Ihr Mikrosegmentierungsprojekt ein voller Erfolg wird.
CI/CD und IaC
Die Integration, das Delivery und Deployment von Code gehören heute zum State-of-the-Art, beinhalten aber verschiedenste, auch nicht-technische Herausforderung, welche es zu meistern gilt.
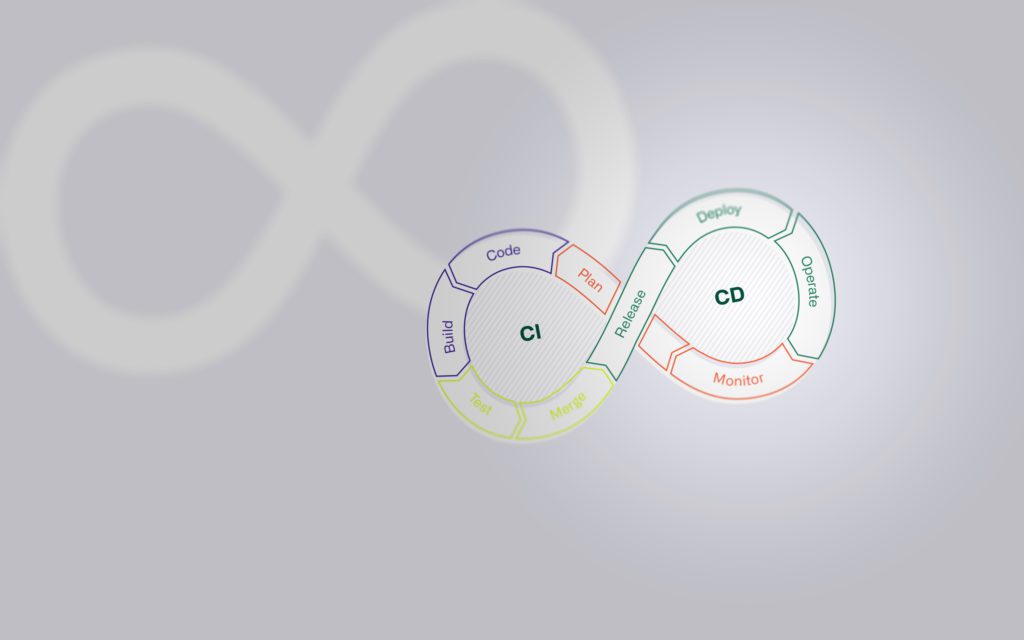
In diesem Blogbeitrag stellen wir Continuous Integration, Continuous Delivery sowie Continuous Deployment (CI/CD) vor und zeigen auf, welchen Mehrwert mit dessen Einsatz gewonnen wird. Weiter wird im Beitrag erläutert, welche Rolle CI/CD im Infrastructure as Code (IaC)- Ansatz spielt und welche Deployment-Varianten On-Prem und in der Cloud existieren.
Einleitung – Konzept CI/CD
Nur selten verlief in der Zeit vor CI/CD die Integration von Änderungen an einem digitalen Produkt reibungslos. Die ganzheitliche Betrachtung und Prüfung aller Abhängigkeiten zwischen neuem und bestehendem Code gestalteten sich schwierig und oftmals waren aufwändige Nachbesserungen des Codes notwendig, bevor dieser letztendlich ins produktive System integriert werden konnte.
Mit den Prozessen, Techniken und Tools des Konzepts CI/CD wird eine Prämisse geschaffen, welche die kontinuierliche und sofortige Integration von neuem oder geändertem Code in die bestehende Lösung ermöglicht. Mittels CI/CD können Anwendungen kontinuierlich über ihren gesamten Lebenszyklus (Software Development Life Cycle, oder kurz: SDLC) von der Integrations-, über die Testphase, bis hin zur Auslieferung und Bereitstellung der Anwendung, automatisiert überwacht werden. Die im Rahmen von CI/CD eingesetzten Praktiken werden zusammenfassend als „CI/CD-Pipeline“ bezeichnet. Die Entwicklungs- und Betriebsteams, die nach dem DevOps-Ansatz arbeiten, werden damit unterstützt.
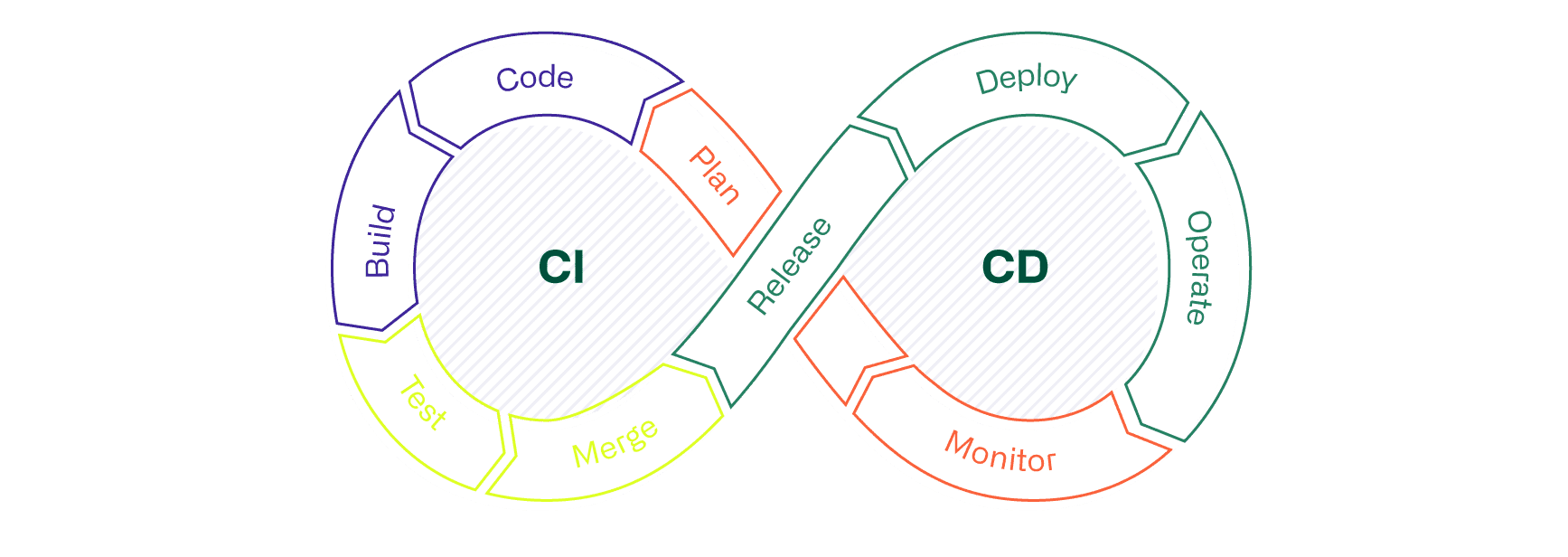
CI/CD im Einsatz von IaC
Der Einsatz einer CI/CD-Pipeline ist unter anderem auch im Infrastructure as Code (IaC)-Ansatz von zentraler Bedeutung. Im Rahmen von IaC werden, nebst der Automatisierungslogik, unterschiedliche Eigenschaften von hardware- und softwarebasierten Infrastrukturkomponenten aus der Cloud oder On-Prem in einem Repository abgelegt. Bei solchen, in Dateien abgespeicherten Eigenschaften muss es sich nicht um 1:1-Kopien aktueller Konfigurationen handeln. Oftmals werden parametrisierte Dateien, beispielsweise in der YAML-Notation, bevorzugt. Der grosse Vorteil liegt darin, dass die Informationen in den Konfigurationsdateien im Repository, trotz eines hohen Automatisierungsgrades, immer noch von einer Person gelesen (human-readable) und verstanden werden können. Ob human-readable oder nicht, in jedem Fall ist die CI/CD-Pipeline, die Voraussetzung für eine automatisierte, transparente und kontinuierliche Validierung von Konfigurationsdateien und der anschliessenden Integration von Änderungen in der Infrastruktur.
Continuous Integration (CI)
CI besteht aus dem automatisierten Prozess, welcher die kontinuierliche Integration von Anpassungen einer Anwendung sicherstellt. Continuous Integration unterstützt die Entwickler dabei regelmässig Änderungen am Code vorzunehmen und zu veröffentlichen. Mittels automatisierten Prüfprozessen wie Codeanalysen oder Unit-Tests (Codetests) wird sichergestellt, dass bearbeitete Branches im Code-Repository so zusammengeführt werden können, damit die Anwendung weiterhin funktioniert. Der Branch eines Repository gehört zum Entwicklungsprozess und kann als einen Zweig mit Verweis auf den bestehenden, validierten Code angesehen werden. Müssen Entwickler Änderungen am bestehenden Code vornehmen, wird zuerst ein neuer Branch erstellt, in welchem die Änderung oder Weiterentwicklung erfolgen. Anhand eines «Merges» werden anschliessend die finalen Anpassungen am Code mit dem bestehenden Code im Repository zusammengeführt.
Zusammengefasst enthält die erfolgreiche CI das automatisierte
- Erstellen der angepassten Anwendung (Build)
- sowie deren Testen (Test)
- und das Zusammenführen des geänderten Codes in einem Code-Repository wie beispielsweise GitHub (Merge).
Sofern nicht anders konfiguriert, ist ein Merge erst dann erfolgreich, wenn alle definierten Prozesse (Jobs) innerhalb der «CI/CD-Pipeline» erfolgreich durchgelaufen sind.
Continuous Delivery (CD)
Der Abkürzung «CD» werden zwei Bedeutungen zugeschrieben. Einerseits Continuous Delivery, anderseits Continuous Deployment. Diese ähnlichen Konzepte werden oftmals synonym verwendet. Im Rahmen beider Konzepte werden die, auf CI nachfolgenden, automatisierten Prozesse in der Pipeline gestaltet. Teilweise wird anhand der Begriffe Continuous Delivery und Continuous Deployment die Ausprägung der Automatisierung konkretisiert. Was das heisst, wird in diesem Blog im Abschnitt Continuous Deployment erläutert. Ein, in die Pipeline integriertes CI ist die Voraussetzung für einen effizienten CD-Prozess. Das Continuous Delivery ermöglicht nach erfolgreicher Code-Validierung durch die CI die automatisierte Bereitstellung von Anwendungen in eine oder mehrere Umgebungen. Entwickler nutzen üblicherweise Umgebungen für die Build-, Test- und Deploy-Phase. Mögliche Prozesse (Jobs) aus den verschiedenen Phasen gibt es viele.
Zum Beispiel können dies
- das Erstellen eines Builds der Anwendung,
- das Verwalten und die Schemavalidierung von Umgebungsvariablen, die eine ganze Infrastruktur oder einzelne Komponente davon definieren,
- das Testen und Zurücksetzen einer Umgebung oder spezifischer Komponenten davon, falls die Tests fehlschlagen
- und viele weitere Aktivitäten sein.
Das erfolgreiche Durchlaufen aller Continuous Delivery-Phasen erlaubt dem Operation-Team die rasche und unkomplizierte Bereitstellung einer validierten Anwendung oder Infrastrukturkonfiguration für die Produktion.
Continuous Deployment (CD)
Das Continuous Deployment ist eine Erweiterung des Continuous Delivery. Continuous Deployment ermöglicht das Automatisieren der Freigaben von Anpassungen einer App oder auch von Infrastrukturkonfigurationsdateien. Continuous Deployment erlaubt folglich eine nahtlose und schnelle, teils in wenigen Minuten erfolgte Integration von Code-Anpassungen in ein produktives Umfeld. Möglich machen dies durchdachte und umfangreiche, automatische Tests innerhalb der verschiedenen Phasen in der CI/CD-Pipeline. Ein voll automatisiertes Deployment ist aber nicht immer sinnvoll. Können die automatischen Prüf- und Testelemente der Pipeline das Einhalten aller Richtlinien und somit die Gewährleistung der Governance aufgrund bestimmter Gegebenheiten nicht abdecken, so muss das Deployment manuell erfolgen. Zumindest bis die notwendige Prämisse geschaffen wurde. Dies kann anhand von Verbesserungen wie Standardisierung, dem Anpassen bestehender Prozesse (sofern möglich), dem Auflösen von externen Abhängigkeiten oder deren Berücksichtigung mittels Zugriffs über eine Schnittstelle, usw. ermöglicht werden.
CD/CD und IaC – Deployment-Varianten
In der Cloud wie auch On-Prem bieten sich verschiedene Use-Cases an, welche sich für CI/CD eignen. Beispielsweise können durch das DevOps-Team serverless oder mittels Container-Technology schnelle, automatisierte Code-Updates verteilt werden. Je nach Zielarchitektur und Umfang der Anpassung bieten sich verschieden Verteilungsansätze an. Die nachfolgende Auflistung enthält die drei bekanntesten, welche in der Cloud und On-Prem eingesetzt werden können.
| CI/CD – Verteilungsansätze |
| Das Blue-Green Deployment sieht eine Entwicklung auf parallel dedizierten Infrastrukturen vor. In der Produktionsumgebung (blue) befindet sich die letzte, funktionierende Version von Anwendungen oder Anpassungen an der Infrastruktur. In der Staging-Ebene (green) werden die angepassten Anwendungen oder die durch angepasste Konfigurationsdateien veränderte Infrastruktur (IaC) umfänglich auf ihre Funktionen und Performance getestet. Dieser Deployment-Ansatz ermöglicht effizientes Implementieren von Änderungen, kann aber, je nach Komplexität der Produktionsumgebung, kostenintensiv sein. |
| Mittels Rolling Deployment werden Anpassungen inkrementell verteilt. Dies reduziert das Risiko von Ausfällen und ermöglicht bei Problemen einfache Rollbacks auf den zuvor funktionierenden Zustand. Folglich müssen als Voraussetzung für eine rollierende Verteilung, die Services mit der alten und neuen Version kompatibel sein. Je nachdem sind dies Anwendungsversionen oder im Fall von IaC Infrastrukturkonfigurationsdateien. |
| Das Side-by-Side Deployment ähnelt dem Blue-Green Deployment. Im Unterschied zu Blue-Green werden die Änderungen nicht über zwei Umgebungen verteilt, sondern direkt einer ausgewählten Benutzergruppe produktiv zur Verfügung gestellt. Sobald die Benutzergruppe, die in der CI/CD-Pipeline zuvor getesteten Funktionen und Performance bestätigt, können die Updates an alle übrigen Benutzer verteilt werden. Dies ermöglicht den Entwicklern, gleich wie beim Rolling-Deployment, den Parallelbetrieb verschiedener Versionen und zusätzlich das Einholen von echten Benutzer-Feedbacks, ohne hohes Risiko von Ausfallzeiten. |
Eine Empfehlung der Deployment-Variante ist situativ und hängt vom zu verteilenden Produkt und von der Infrastruktur ab.
Nachfolgend beschreiben wir einen exemplarischen Auszug von Lösungen für CI/CD und IaC-Vorhaben:
| Terraform | Projekt von HashiCorp, welches sehr flexibel einsetzbar und kompatibel mit bekannten Cloud-Anbietern wie AWS, Azure, GCP und OpenStack ist. |
| Ansible | Projekt von Red Hat, das als Orchestrierungs- und Konfigurationstool das Automatisieren von repetitiven und komplexen Prozessen mittels Playbooks ermöglicht. |
| AWS CloudFormation | IaC Service, welcher das Verwalten, Skalieren und Automatisieren von AWS-Ressourcen mittels Templates innerhalb der AWS-Umgebung ermöglicht. |
| Azure Resource Manager | IaC Tool der Azure Umgebung, welches unter anderem das Deployment sowie Verwalten von Azure Ressourcen mittels ARM Templates ermöglicht. |
| Google Cloud Deployment Manager | Infrastruktur Deployment Service von Google, welcher das Erstellen, Provisionieren und Konfigurieren von GCP Ressourcen mittels Templates und Code ermöglicht. |
| Chef | Bekanntes IaC Tool, das aufgrund seiner flexiblen Einsatzmöglichkeit und dem Bereitstellen einer eigenen API zusammen mit Terraform in AWS, Azure und GCP eingesetzt werden kann. |
| Puppet | Ähnliches Tool wie Chef, welches auch häufig für das Überwachen definierter und provisionierter IaC-Eigenschaften und zur automatischen Korrektur von Abweichungen zum Soll-Zustand eingesetzt wird. |
| Vagrant | Weitere Lösung von HashiCorp, welches ein schnelles Erstellen von Entwicklungsumgebungen ermöglicht und für kleinere Umgebungen mit einer geringen Anzahl VMs ausgerichtet ist. |
Im hybriden Cloudumfeld reichen die hauseigenen CI/CD- und IaC-Lösungen der Cloud-Plattformen wie AWS, GCP und Azure in der Regel nicht aus. Beispielsweise können Terraform und Ansible aufgrund ihrer hohen Flexibilität und Kompatibilität vor allem in Multicloud-Umgebungen eine passende Lösung für IaC sein.
Blog
Multicloud
Erfahren Sie in unserem Blogbeitrag über Multicloud, was es sonst noch so hinsichtlich Multicloud-Szenarien zu beachten gilt.
Implementation – Chance und Herausforderungen
Anhand der Implementation von CI/CD kann von diversen Chancen profitiert werden. Die wichtigsten Chancen sind in der nachfolgenden Auflistung exemplarisch zusammengefasst:
| Chancen |
| Kürzere Einführungszeiten in die Produktion und schnelles Feedback – Anhand des automatisierten Testens und der Validierung in der CI/CD-Pipeline entfallen mühsame, manuelle und somit zeitaufwändige Schritte. |
| Robustere Releases & frühere Erkennung von Fehlern (Bugs) – Ausgiebiges Testen von Code und Funktionen. Einfache Fehler werden vermieden. |
| Hohe Visibilität (Transparenz) – Mittels CI/CD-Pipeline können einzelne Testergebnisse im Detail geprüft werden. Werden Mängel oder Fehler in neuem Code entdeckt, so wird dies transparent aufgezeigt. |
| Kostenreduktion – Reduzierung der Kosten anhand Reduktion simpler Fehler. Langfristig gesehen ist die Nutzung von CI/CD aufgrund der Automatisierung weniger fehleranfällig und somit nachhaltig günstiger. |
| Höhere Kundenzufriedenheit – Der konsistente und zuverlässige Entwicklungsprozess resultiert in zuverlässigeren Releases, Updates und Fehlerbehebungen. Dies steigert die Kundenzufriedenheit. |
Für die Implementation und den Betrieb von CI/CD müssen aber auch diverse Herausforderungen gemeistert werden. Eine der grössten und wichtigsten ist die Standardisierung in der eigenen Infrastruktur. Sie bestimmt die Ausprägung des Automatisierungsgrads zu einem grossen Teil. Im Allgemeinen kann davon ausgegangen werden, dass eine homogene Infrastruktur prinzipiell einen hohen und kosteneffizienten Automatisierungsgrad ermöglicht. Heterogene Umgebungen sollten weitgehendst standardisiert werden, sofern eine hohe Automatisierung das Ziel ist. Dabei gilt es zu beachten, dass das Einführen oder lediglich Erhöhen der Standardisierung bereits für sich, ein grösseres Vorhaben sein kann. Weitere Herausforderungen, die es zu meistern gilt, sind:
| Herausforderungen |
| Anpassungen in der Unternehmenskultur – CI/CD wird im Rahmen agiler Unternehmenskulturen und Vorgehensweisen, speziell DevOps, genutzt und gelebt. Folglich müssen die Teams sich in der iterativen, agilen Arbeitsweise wohl fühlen und mit ihr vertraut sein. |
| Fachwissen – Eine korrekte Implementierung von CI/CD setzt viel Fachwissen und Erfahrung voraus. Nicht nur im technischen, sondern auch im organisatorischen Bereich. |
| Reactive Resource Management – Um die Performance über alle automatischen Prozesse von CI/CD auch bei erhöhter Beanspruchung zu gewährleisten, sollte das Ressourcenmanagement überwacht und reaktionsfähig sein. |
| Initiale Entwicklungskosten – Die initialen Aufwände für eine Entwicklungsumgebung, den Knowhow-Aufbau, die Konzeptionierung, Standardisierung und Prozessanpassung können zwar hoch ausfallen, sind aber durch den gewonnenen Mehrwehrt von CI/CD gerechtfertigt. |
| Microservice Environment – Um eine hohe Skalierbarkeit zu gewährleisten, wird idealerweise eine Microservice-Architektur aufgebaut. Die Architekturverantwortlichen müssen sich der einhergehenden Zunahme der Komplexität und Abhängigkeiten und der Anforderung für deren Administration bewusst sein. |
Unsere Einschätzung
Der Aufbau und das Design von CI/CD hängt vom Setup in der eigenen Entwicklungs- und Infrastrukturumgebung ab. Unserer Einschätzung nach existiert kein fertiges Konzept für die CI/CD-Pipeline. Welche Tests und Validierungen in der Continuous Integration, welche Phasen im Continuous Delivery implementiert und wie die Verteilung im Rahmen von CD erfolgt, muss trotz diverser Best Practice-Ansätze individuell eruiert und konzeptioniert werden. Zumindest zu Beginn wird das notwendige Knowhow in den verschiedenen Fachgebieten wie der Softwareentwicklung, der Quality-Assurance und speziell im IaC-Ansatz, auch das vorhandene Fachwissen in den verschieden Infrastrukturbereichen oftmals vernachlässigt.
Der IaC-Ansatz bietet eine visionäre, bereits in der Praxis erprobte Lösung an, welche es ermöglicht Infrastruktur und dessen Services On-Prem wie auch in der Cloud adaptiv, leicht wartbar und sicher zu gestalten. CI/CD bildet dabei ein Kernelement, welches die korrekte und transparente Abbildung der Konfigurationen aus einem zentralen Repository auf Infrastrukturkomponenten ermöglicht. Wie in diesem Blogbeitrag erläutert, lohnt sich der Einsatz von CI/CD. Die kostengünstigen und kurzen Einführungszeiten von Änderungen in die Produktion, robustere Releases und die dadurch erhöhte Kundenzufriedenheit sind nur einige von vielen Chancen, welche CI/CD bietet. Damit diese Chancen genutzt werden können, muss die Implementierung wie auch der Betrieb von CI/CD erfolgreich bewältigt werden. Es gilt Herausforderung wie eine hohe Standardisierung in der IT-Landschaft, mögliche Anpassung in eine agile Organisationsform wie auch die Beschaffung des Fachwissens zu meistern.
Gerne unterstützen wir Sie bei der Analyse, wo Sie hinsichtlich Anforderungen für den Einsatz von CI/CD stehen (Standardisierungsgrad, Organisationsform, usw.) und bei der Evaluierung sowie Konzeption möglicher CI/CD-Lösungen in der Cloud.
Unsere langjährige Erfahrung in den essenziellen Disziplinen setzen wir gewinnbringend für Ihre individuelle Cloud Journey ein. Mit unserer Unterstützung meistern Sie die Hot-Topics wie; Network, Organization, Availability, Automation, CI/CD, IaC, Governance/Compliance, Security & Cost Management.
Cloud Netzwerkintegration
Egal, welche Cloudstrategie umgesetzt werden soll, ist es sinnvoll, das lokale Datacenter mit der Cloud zu verbinden, da der Weg in die Cloud einem schrittweisen Vorgehen entspricht. Es gibt immer Services im lokalen Datacenter, die einen Zugriff von der Cloud benötigen. So zum Beispiel Directory- und Identity Services, oder auch Zugriffe auf Datenbanken sowie die DDI Integration.
Cloud Anbindung
Die Art, wie die Anbindung realisiert wird, ist jedoch abhängig von der geforderten Qualität. Je nach Use-Case müssen vorgängig folgende Fragen gestellt und beantwortet werden.
Thema
Erforderliche Qualität
Frage
- Welche Qualität (Verfügbarkeit, Loss, Delay Jitter) der Anbindung wird für meinen Use-Case benötigt?
- Benötige ich vom Service Provider eine Qualitätsgarantie?
Anbindungs-Variante
- Kann die geforderte Qualität mittels IPSec VPN erreicht werden, oder ist eine direkte Anbindung (z.B. Express Route) erforderlich?
- Kann ich die DC-Anbindung in ein bestehendes SD-WAN integrieren?
Es sei angemerkt, dass in der Cloud für IaaS und PaaS in erster Linie virtuelle Netze mit privaten IP-Adressen (RFC 1918) erstellt werden, welche dann via der DC-Cloud Anbindung geroutet werden. SaaS Services, wozu auch das Cloud-Portal gehört, sind mit öffentlichen IP Adressen adressiert und werden via dem Internetzugang zugegriffen, welcher auch für das Surfen im Internet verwendet wird.
Diese Grafiken zeigen die Möglichkeiten der Anbindung einer Public Cloud ans lokale DC.
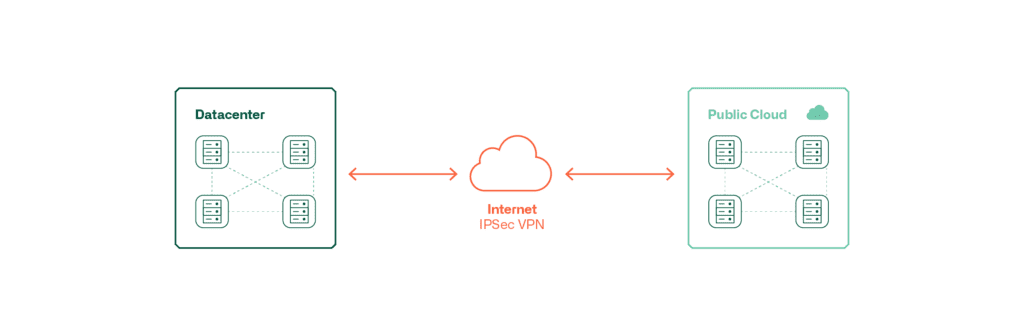
Diese Art der Anbindung ist kostengünstig und relativ schnell zu realisieren. Allerdings ist diese Art der Anbindung nicht für alle Qualitätsanforderungen geeignet.
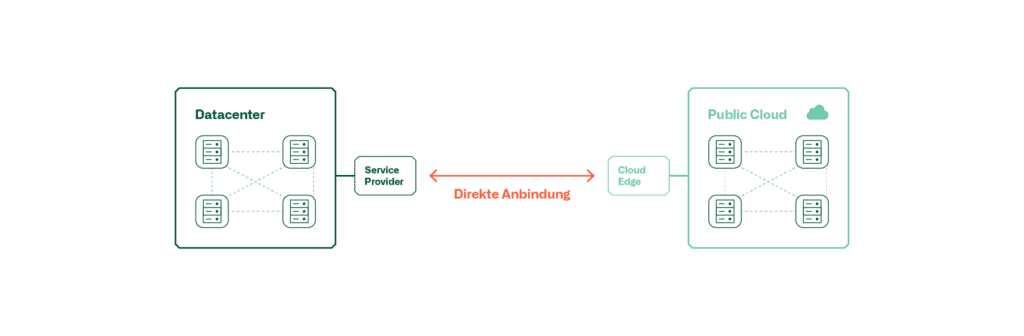
Für hohe Qualitätsanforderungen eignet sich eine direkte Anbindung der Cloud ans lokale Datacenter. Eine solche Anbindung erfolgt jeweils über einen Service Provider, welcher im entsprechenden Land diese Dienste anbietet. Auch hier wird die Verbindung in der Regel verschlüsselt.
Eine weitere Variante stellt SD-WAN dar, welche in der Regel mit der Anbindung der Benutzer einhergeht. SD-WAN stellt eine Plattform dar, auf welcher verschiedene IPsec VPNs mit unterschiedlichen Topologien und Transportnetzwerken realisiert, und zentral gemanagt werden können. Sowohl die Variante IPsec VPN, sowie die direkte Anbindung lassen sich mit SD-WAN realisieren, respektive im Falle der direkten Anbindung als Transport integrieren.
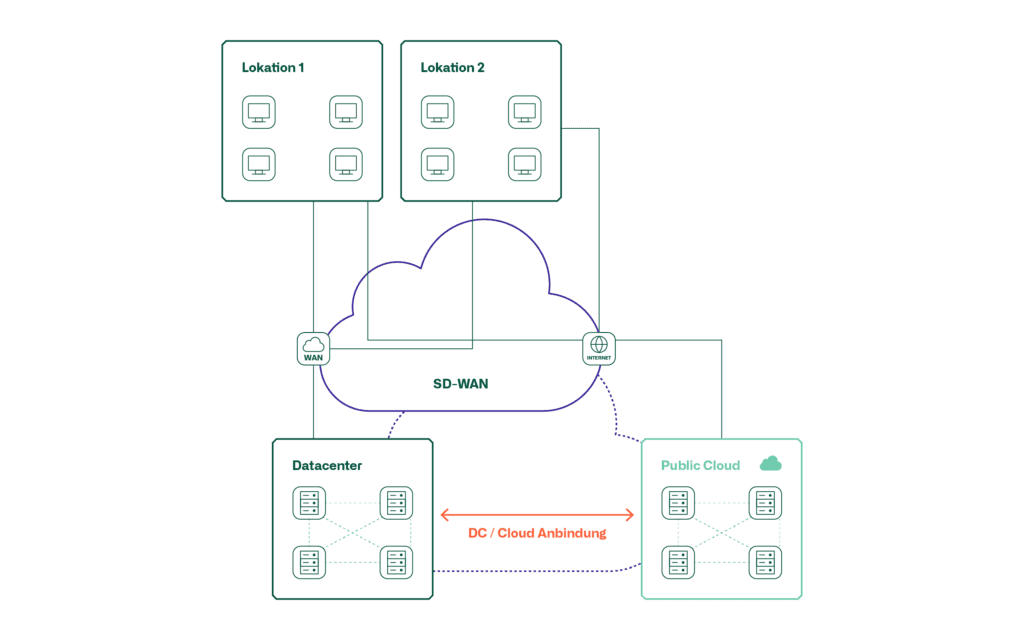
Die folgende Tabelle zeigt auf, welche Anbindungsvarianten für die verschiedenen Use-Cases geeignet sind.
Variante
Internet IPsec VPN
Empfehlung
Diese Art der Anbindung ist für die Grundbedürfnisse ausreichend, sofern keine Garantie seitens des Service Providers notwendig ist. Es empfiehlt sich, die Verbindung mittels einem TIER 2 Internet Provider zu realisieren.
Direkte Anbindung
Ist für alle Use-Cases und Qualitätsanforderungen geeignet. Da diese Variante auch höhere Kosten verursacht und aufwendiger zu implementieren sind, dürfte sie für Use-Cases, welche temporärer Natur sind, nicht in Frage kommen.
SD-WAN
Sofern SD-WAN bereits für die Anbindung der Benutzer existiert, empfiehlt es sich, SD-WAN auch für die DC-Anbindung einzusetzen, da wie bereits erwähnt, auch die direkte Anbindung in der Regel verschlüsselt wird.
Cloud Networking
Neben der Anbindung ans lokale DC stellt sich die Frage, welche funktionalen Anforderungen ans Cloud Networking gestellt werden. Dabei geht es einerseits um Netzwerkkomponenten wie Router, VPN Gateways und Loadbalancer sowie um die Frage, ob eine lokal im DC eingesetzte Fabric-Technologie in die Cloud verlängert werden soll.
Thema
Netzwerk-Komponenten
Frage
- Was sind meine funktionalen Anforderungen an die Cloud Netzwerkkomponenten?
- Erfüllen die Cloud native Netzwerkkomponenten diese Anforderungen oder muss ich virtuelle Appliances von Netzwerkkomponenten in der Cloud einzusetzen?
DC Fabric Integration
- Soll die im lokalen DC eingesetzte Fabric-Technologie in die Cloud erweitert werden? (z.B. Cisco ACI oder VMware NSX)
Die Frage betreffend der Netzwerkkomponenten in der Cloud lässt sich aus funktionaler Sicht wie folgt beantworten.
Variante
Cloud-native
Empfehlung
Wo immer möglich sollten Netzwerkkomponenten vom Cloud Provider, sogenannte Cloud-native Komponenten, eingesetzt werden. Für die Standard Layer 2 und Layer 3 Funktionen sind diese normalerweise ausreichend.
Virtuelle Appliances
Falls die Cloud-native Komponenten gewisse Funktionen nicht unterstützen, werden in der Regel virtuelle Appliances eingesetzt. Dies vor allem für Loadbalancer, VPN Gateways sowie Übergänge von Legacy Networking nach SDN-Networking (ACI oder NSX).
Ob eine DC Fabric in die Cloud erweitert werden soll ist abhängig davon, welche Cloudstrategie verfolgt wird. Wird die Cloud über längere Zeit im Hybrid-Modus betrieben und soll die Netzwerk-Segmentierung in der Cloud mit den gleichen Tools bewerkstelligt werden, dann ist es sinnvoll, die lokale DC Fabric in die Cloud zu verlängern. Wird die Cloud jedoch temporär eingesetzt, dann macht eine solche Verlängerung wenig Sinn. Um die lokale DC Fabric in die Cloud zu erweitern, sind im Falle von Cisco ACI Cloud-seitig «Cisco Cloud ACI» und im Falle von VMware NSX «VMware NSX Cloud» zu implementieren und zu aktivieren. Diese stehen in den entsprechenden Cloud-Stores zur Verfügung.
Unsere Consultants haben in unzähligen Cloudprojekten von der Konzeptionierung bis zur Einführung das erforderliche Know-How aufgebaut und weiterentwickelt. Wir unterstützen unsere Kunden, um ihre Cloudprojekte ganzheitlich, also über die Netzwerkebene hinausgehend, erfolgreich durchzuführen.
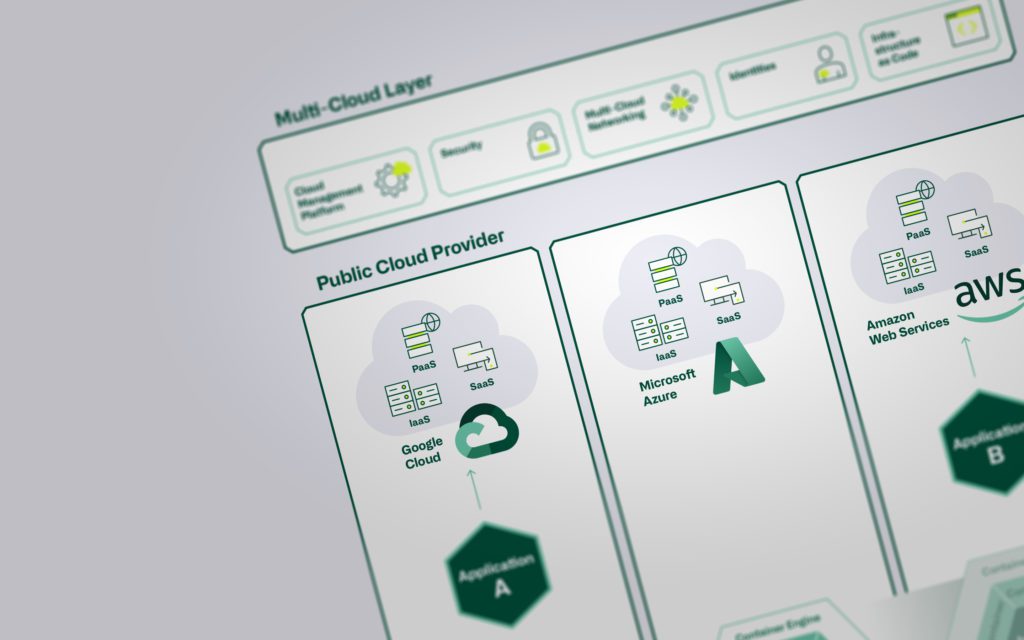
Multicloud – Macht das wirklich Sinn?
Mit diesem Blog gehen wir darauf ein, was unter Multicloud zu verstehen ist, für welche Organisationen es wirklich einen Mehrwert bietet und was für eine erfolgreiche Implementation unternommen werden muss.
Was ist Multicloud?
Was verstehen wir, als atrete Cloud Consultants, unter Multicloud denn genau? Sofern Services von mehreren Cloud Providern (z.B. Microsoft Azure, Google Cloud Platform (GCP), Amazon Web Services (AWS), oder kleinere Anbieter) bezogen werden, sprechen wir von einem Multicloud-Szenario. Hierbei spielt das Deployment- (Public, Private) oder das Service-Modell (IaaS, PaaS, SaaS) keine Rolle. Wir gehen davon aus, dass sich heute fast jede Organisation – bewusst oder unbewusst – in einem Multicloud-Szenario befindet.
Wir unterscheiden hier zwischen Multicloud «Servicebezug» und «Servicebereitstellung». Im Bereich des Servicebezugs sehen wir, dass SaaS-Applikationen in der Regel ohne Probleme von beliebigen Providern bezogen werden. Im Bereich der Servicebereitstellung gehen wir davon aus, dass Applikationen zur Generierung von Eigen- oder Kundennutzen wohl auf verschiedenen Cloud-Plattformen betrieben werden könnten, dies jedoch mit viel grösseren Hürden und höherer Komplexität verbunden ist.
Wird eine Applikation effektiv in einem Multicloud-Setup bereitgestellt, sollte das Ziel sein, dass sie jederzeit basierend auf vordefinierten Trigger (Verfügbarkeit, Kosten, Location, …) voll automatisiert auf andere Provider verschoben oder umgeleitet werden kann. Eine solide Cloud-Strategie sollte die entsprechenden Rahmenbedingungen hierfür vorgeben.
Im weiteren Verlauf dieses Blogs gehen wir vertiefter auf die Aspekte der Multicloud-Servicebereitstellung von eigenen Services ein und lassen den Servicebezug für sich ruhen.
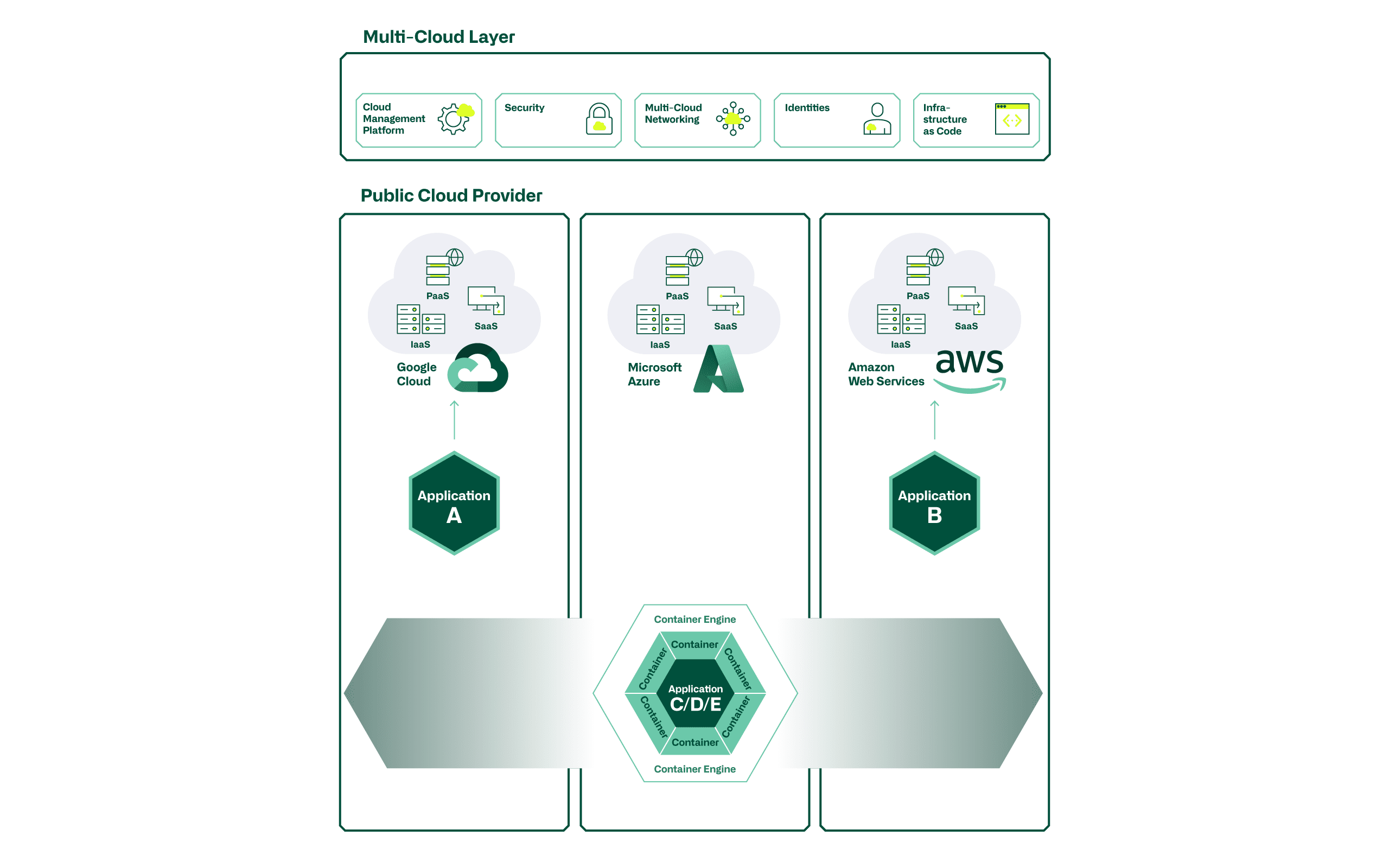
Einsatzgebiete für Multicloud
Grundsätzlich stellt sich die Frage, warum überhaupt eine Servicebereitstellung im Multicloud-Setup gewählt werden soll. Bedingt dadurch, dass sich jede Cloud ein wenig von den anderen unterscheidet, wird die Wahl der Zielplattform(en) getrieben durch den effektiv zu implementierenden Use Case. Hier spielen längst nicht mehr nur Kostenaspekte eine Rolle. Die wohl wichtigsten Unterscheidungsmerkmale und Gründe für den Betrieb einer Applikation auf einem spezifischen Cloud Provider, liegen in den Plattform Services (Serverless-Functions, BigData-, Database-, Machine Learning-, IoT- oder AI-Services).
- So kann es zum Beispiel Gründe geben, einen BigData Analytics UseCase auf AWS, oder einen IoT UseCase auf Azure aufzubauen, da spezifische Stärken, oder eine optimale Integration eines Cloud Providers genutzt werden möchten.
Wird also in der Applikationsentwicklung ein spezifischer Service eines Providers integriert, z.B. eine Serverless Database von AWS (Amazon Aurora) steht bei einem anderen Provider wohl ein Pendant (z.B. Azure SQL Managed Instance) zur Verfügung, welche sich jedoch nicht über die gleichen API Calls ansteuern lässt. Bei einer Portierung einer Applikation auf einen anderen Provider müssen somit signifikante Anpassungen durchgeführt werden. Die Platform Services sind somit auch einschränkendes Element in der Implementierung einer Multicloud-Architektur.
Um eine Applikation also effektiv im providerunabhängigen Multicloud-Setup betreiben zu können (horizontal von Provider zu Provider verschiebbar), gilt es diese infrastrukturunabhängig zu entwickeln.
- Ein exemplarischer Use Case hierfür ist z.B. ein stateless Web Frontend für kundenseitig eingesetzte Webauftritte. Erreichbar ist dies mit Container-Technologien wie z.B. Docker und Kubernetes.
Vor- und Nachteile
Mit der Implementierung von Multcloud-Szenarien entstehen Vorteile und natürlich auch Nachteile. Exemplarisch wollen wir hier ein paar davon auflisten:
Pros
- Best of Breed – Stärken der Anbieter effektiv nutzen
- Vendor Lock-in vermeiden – geringere Abhängigkeit von einzelnem Provider
- Global-Reach – Erweiterung der Availability-Zones und gleichzeitige Reduktion der Latencies
- High Availability Design – Redundanzen über mehrere Provider aufbauen
- Compliance – Erreichen von internen & externen Vorgaben
Cons
- Traffic-Kosten – Transfer von einem Provider zum anderen verursacht Kosten (egress Traffic)
- Verlust der Integrationsvorteile – Einschränkungen in den Plattform Services der Provider (PaaS)
- Erhöhung der Komplexität auf mehreren Ebenen (Architektur, Service Management, Provider Management, …)
- Skillset der Mitarbeiter muss auf allen Providern vorhanden sein, was hohe Kosten verursacht
- Reduzierte Skaleneffekte (z.B. bei Billing Models) im Vergleich zu einem einzelnen Provider
Vermeintlichen Vorteilen stehen bedeutende Nachteile gegenüber. Jede Organisation muss die für sich relevanten Themenbereiche analysieren und beurteilen. Ein allfälliges Multicloud-Szenario gilt es evolutionär zu entwickeln und die Rahmenbedingungen sind in Perfektion zu managen. Nur so können anvisierte Mehrwerte auch tatsächlich erreicht werden. Im nächsten Abschnitt gehen wir detaillierter darauf ein.
Rahmenbedingungen
In den nächsten Abschnitten thematisieren wir die wichtigsten Rahmenbedingungen. Grundsätzlich gelten sie auch in einem Singlecloud-Ansatz, müssen im Multicloud-Szenario jedoch in operativer Exzellenz gemanagt werden.
«Infrastructure as Code» (IaC) und somit die vollständig codebasierte Konfiguration sämtlicher Ressourcen ist ein Schlüsselelement sämtlicher Cloud-Vorhaben. Nur so können die Qualität in wiederkehrenden Tätigkeiten sichergestellt und Infrastrukturen vollständig automatisiert bereitgestellt und wieder abgebaut werden. Für die Digitalisierung ist die Automatisierung somit ein Schlüsselelement, um Ressourcen schnell und qualitativ hochstehend anhand der Kundenbedürfnisse auf den jeweiligen Plattformen bereitstellen zu können.
Um die Serviceerbringung über mehrere Provider hinweg sicherstellen zu können, gilt es ein performantes und sicheres «Multicloud-Netzwerk» zu betreiben. Die nahtlose Kommunikation zwischen allen verwendeten Services und Ressourcen gilt es dabei über alle involvierten Provider zu ermöglichen und entsprechend zu steuern.
Die daraus resultierenden potenziellen Einfallstore für Hacker oder Schadsoftware müssen analysiert und mittels entsprechenden «Security Solutions» bestmöglich reduziert werden.
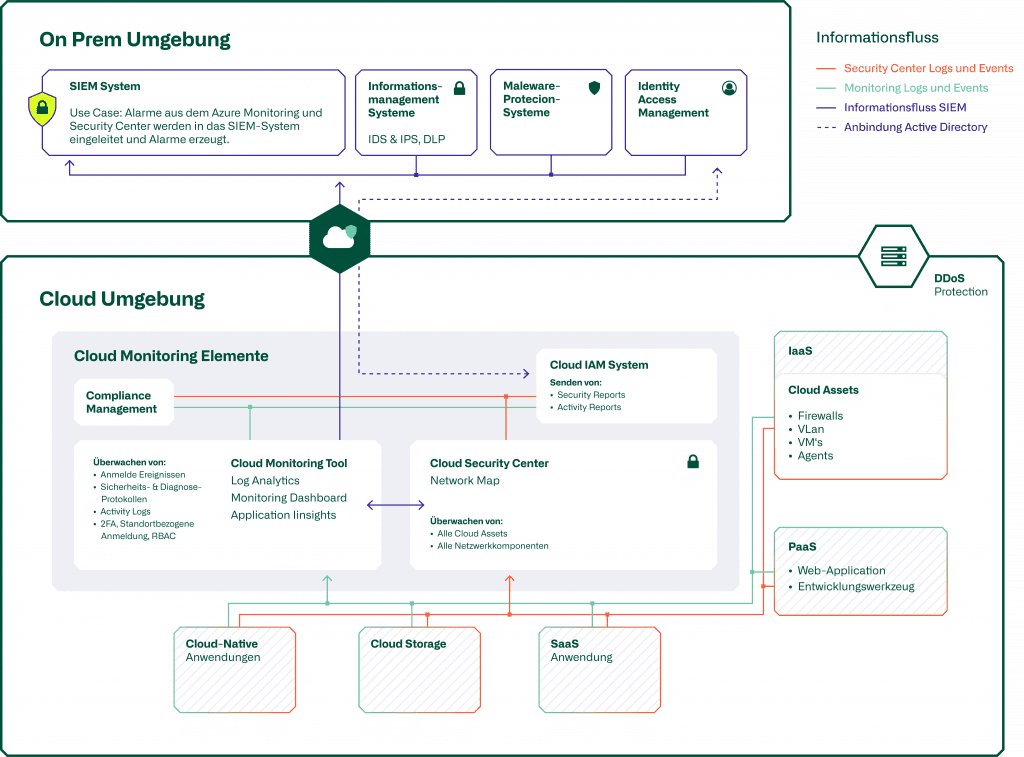
Blog
Cloud Security Monitoring
Ergänzende Informationen zu diesem Thema finden Sie in unserem dedizierten Blog-Beitrag.
Mittels «Cloud Management Plattformen» (CMPs) lassen sich die Cloud-Umgebungen (Infrastrukturen & Services) überwachen und steuern. Sie bieten den Überblick und die Kontrolle über Orchestrierung, Security, Monitoring, anfallende Kosten und Optimierungsmöglichkeiten, so dass das volle Potential genutzt und die Infrastrukturen effizient betrieben werden können.
Im Multicloud-Szenario ist ein schlagkräftiges und hoch qualifiziertes Team mit entsprechendem «Knowhow/Skillset» über alle Provider und die eingesetzten Technologien essenzieller denn je. Die Komplexität mit mehreren Providern steigt bedeutend und die sich stetig verändernden Services müssen proaktiv und mit hoher Qualität gemangt werden.
Als letzte und mitunter wichtigste Rahmenbedingung sehen wir die «Standardisierung». Da im Multicloud-Setup ja grundsätzlich eine Applikation nicht nur auf einer Providerplattform lauffähig sein muss, sondern auch auf allen anderen potenziellen Plattformen, müssen alle Servicebausteine so standardisiert und abstrahiert sein, dass sie überall betreibbar sind. In anderen Worten, spezifische PaaS-Services einzelner Provider können nicht verwendet werden, da sonst die Portabilität nicht sichergestellt ist. Eine Lösung hierfür ist sicher, dass die Applikationen containerbasiert aufgebaut werden, so dass die direkte Abhängigkeit unterliegender Infrastrukturservices weitgehendst reduziert ist. Weiter können Lösungen implementiert werden, um die Konnektivität und die Infrastruktur-Interoperabilität über die Cloud Provider hinweg sicherzustellen.
Hier ein exemplarischer Auszug von Anbieter/Lösungen für Multicloud-Vorhaben:
| Kubernetes | Open-Source-System zur Automatisierung der Bereitstellung, Skalierung und Verwaltung von containerisierten Anwendungen. |
| HashiCorp | Multicloud-Automatisierungslösungen für Infrastruktur, Security, Netzwerk und Applikationen. |
| VMware | Multicloud-Virtualisierungs-Layer vergleichbar mit den OnPremise Software Defined Datacenter Lösungen. |
| Aviatrix | Multicloud Netzwerk- und Netzwerk-Security Automatisierungslösungen |
Blog
Erfolgsfaktoren für Multiprovider Sourcing
Nebst allen technischen Aspekten zu Multicloud ist es zudem ausserordentlich wichtig, das vertragliche Management aller involvierten Provider im Griff zu haben.
Unsere Einschätzung
Als atrete Cloud Consultants sehen wir, dass sich mittelfristig die meisten KMU für die Servicebereitstellung auf einen einzigen Cloud Anbieter fokussieren sollten. Die operative Excellenz auf den essenziellen Disziplinen kann so am schnellsten erreicht werden. Hier sehen wir als wesentlichste Elemente, dass konsequent auf höchste Verfügbarkeit, skalierende Infrastrukturen und eine volle Automatisierung (Infrastructure as Code) aller Ressourcen gesetzt wird. Sind die «Hausaufgaben» gemacht und besteht ein effektiver Bedarf / Use Case für eine Multicloud-Implementation, gilt es die entsprechenden Rahmenbedingungen dafür zu schaffen.
Wir gehen davon aus, dass es höchstens für kundenseitige Kernprozesse einer Firma sinnvoll ist, diese in einem Multicloud-Setup zu betreiben. Die resultierenden Einschränkungen in der Servicebereitstellung über mehrere Cloud Provider überwiegen in den meisten anderen Fällen. Demnach macht es mehr Sinn, bei allen Applikationen, welche nicht explizit eine Multicloud-Bereitstellung erfordern, innerhalb des Ökosystems eines Providers zu bleiben und das volle Potential der zur Verfügung stehenden Services (PaaS & SaaS) auszunutzen. So gelingt es, die Cloud-Infrastrukturen kosteneffizient zu betreiben.