New Senior Consultant at atrete
Dominick Lusti becomes new Senior Consultant in the Cloud, Connectivity & Datacenter division
Dominick Lusti joined our team as a Senior Consultant in the Cloud, Connectivity & Datacenter division on May 1, 2024. Mr. Lusti enriches us with his extensive experience as a team leader for technology and internal ICT as well as a systems engineer. In his previous position, he was responsible for managing the technology department, designing and implementing customer-specific IT and OT infrastructures and developing and testing security and solution concepts. He holds a Bachelor and Master of Science FHO in Business Informatics and is certified as an Azure Solution Architect Expert.

Media contact:
at rete ag
Marlene Haberer
Phone: +41 44 266 55 83
Email: marlene.haberer@atrete.ch
Advantages and challenges of cloud management platforms
The cloud journey of many companies has long since begun and a large proportion of IT infrastructures and solutions are successfully operated in cloud environments. With this trend, companies are faced with the challenge of already operating a hybrid cloud or multi-cloud environment that includes solutions from different providers. This "best of breed" approach makes it possible to make optimum use of the individual strengths of the providers. At the same time, it brings with it the difficulty that IT teams have to manage, adapt and further develop different cloud environments without losing sight of the cost focus and complying with required guidelines. Cloud management platforms (CMPs) are used to master this task. These tools enable companies to manage multi-cloud and on-premise environments centrally with one platform.
In this blog, we will show you which aspects a cloud management platform covers, where we see the limitations of such tools and what you should look out for when choosing a suitable solution.
What is a cloud management platform?
Central management as a key feature
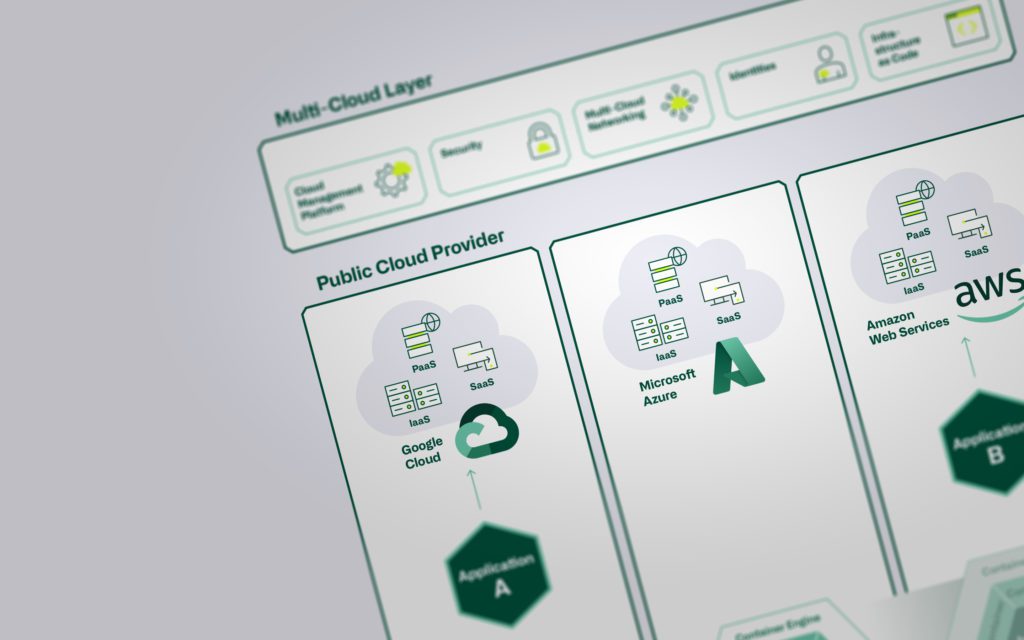
A cloud management platform can be seen as a multifunctional tool that enables centralized management of different cloud providers and on-premises solutions. The main disciplines are in particular the management and optimization of multi-cloud and hybrid cloud environments via a central interface. The platform should be as user-friendly and intuitive as possible so that users can manage their workloads via the graphical interface. A modern and future-oriented CMP supports multi-cloud capability and the integration of on-premises resources.
Find out more about multi-cloud scenarios and why companies are consciously or unconsciously facing this challenge in the following blog post:
Multicloud - Does it really make sense?
The functionalities of cloud management platforms are constantly evolving and the tools are becoming ever more comprehensive. A trend can be seen that larger public cloud providers such as Microsoft Azure, Amazon Web Services (AWS) and Google Cloud Platform (GCP) are expanding their native platforms so that they are not only focused on their own services and infrastructures, but also offer APIs and tools for integration with other platforms and services.
Some providers focus more strongly on individual subject areas and therefore offer specific functionalities. We do not consider these solutions, also known as "mini-suites", to be fully-fledged CMPs. In contrast, other providers pursue a holistic approach with which they cover a broad range of functionality. They achieve this by integrating other products and manufacturers. Let's take a look at the key components of a cloud management platform in the following sections.
Provisioning and orchestration: With a CMP, your IT team can provide workloads as efficiently as possible. This is achieved by automating recurring tasks. Manual intervention should be minimized as far as possible to reduce the time required and potential sources of error.
Service enablement: With service enablement, you can create a service catalog that is individually tailored to your needs. This enables cloud users to order the IT resources they need in a simple and standardized way. The requested resources are then provided automatically and in accordance with internal security requirements.
Monitoring and surveillance: CMPs collect data from all providers and consolidate it for you so that you have an overview of your hybrid and cloud resources via a dashboard. This ensures comprehensive monitoring and seamless surveillance of all IT resources. You can use this data for reporting purposes, for example.
Inventory and categorization: CMPs help you to have a comprehensive overview and control of your infrastructure. Resources are automatically discovered and managed, changes monitored and configurations centrally managed. Missing tags are detected and automatically added according to criteria defined by you.
Cost control and resource optimization: With cost control and resource optimization, CMPs provide detailed insights into your expenses and make it possible to identify unused resources and thus eliminate unnecessary costs. Through automatic scaling, CMPs can help you minimize cloud costs.
Cloud migration, backup and disaster recovery: A CMP supports you in setting up recovery and business continuity architectures. In addition, the central platform gives you comprehensive backup control, allowing you to secure the integrity of your data and protect it from loss.
Identity, security and compliance: With a CMP, you have an overview of security-relevant topics across all cloud platforms. This includes, for example, access monitoring (IAM) as well as dashboards for security compliance in relation to your security guidelines.
The individual subject areas can help you to select evaluation criteria in order to carry out a successful evaluation of a CMP.

Differentiation of tools - what can't CMP solutions do?
Cloud management is a complex domain. This becomes clear as soon as you look at the range of functions. The various providers of CMP solutions continue to align themselves and sometimes focus on individual or related subject areas.
One important aspect that CMPs may not fully cover is the initial creation and configuration of cloud infrastructures. CMPs are primarily designed for the operation and management of existing infrastructures and less for engineering. An infrastructure is usually not set up with a CMP, but with specialized tools such as Terraform or the native platforms. CMPs are added to support the management and optimization of the existing infrastructure. A CMP is primarily intended for the operations team, which monitors and manages the ongoing processes.
While many CMPs offer integrations for Infrastructure-as-Code (IaC) approaches and allow the use of existing Terraform and Ansible scripts, the creation and configuration of the infrastructure remains outside the core functional scope. It is possible to build an infrastructure directly with a CMP, but this is often not practical as CMPs are designed more for management and do not provide the in-depth flexibility and control required for engineering.
The benefits of a CMP depend on the way resources are deployed. Experienced DevOps teams with high IaC maturity often work with code and use fewer graphical interfaces, as text-based configuration files and scripts can be efficiently integrated into their CI/CD pipelines.
You can find out more about the role of CI/CD in the IaC approach in the blog post:
CI/CD and IaC
Furthermore, CMPs may not be able to fully support the specific, proprietary services of all cloud providers, which can lead to limitations in functionality. This is because cloud platforms are constantly evolving and new functionalities are constantly being added while others disappear.
Possible variants and tools
CMPs differ in terms of their operating mode. Some providers offer their solutions as Software-as-a-Service (SaaS), which enables quick implementation and easy maintenance. Others rely on self-hosted solutions, which offer more control and customization options, but also require more administrative effort.
Below you can find a list of some providers of cloud management platforms, the list is not exhaustive:
- BMC Cloud Lifecycle Management
- CloudBolt
- Flexera
- IBM Cloud Pak for Multicloud Management
- Morpheus Data
- Nutanix Cloud Manager
- Red Hat CloudForms
- Scalr
- VMware vRealize Suite
Who needs a CMP and what is the best solution for you?
A cloud management platform is beneficial for various organizations and scenarios. Below we explain possible scenarios and what the advantage of CMPs is for the use case.
This allows companies with a multi-cloud strategy to benefit from the centralized management of different cloud providers via a single user interface. Large companies and corporations use CMPs for centralized control and overview of their extensive IT infrastructures as well as for scaling and managing complex environments. Companies that operate as IT service providers and managed service providers (MSPs) use CMPs to efficiently manage the cloud infrastructures of multiple customers from a central dashboard and to automate processes. Companies that are subject to strict regulations and security requirements use CMPs to comply with legal requirements and industry standards across different cloud environments and to apply security policies consistently. There are many other scenarios where CMPs can be beneficial. These are not limited to specific industries or only relevant to technology companies.
To find the right solution for your company, we recommend that you check why you are using a hybrid cloud or multi-cloud environment. This will help you to find out which functions your future solution should primarily cover. You should also decide which tools will complement each other and which tools you want to replace.
Conclusion
Using a CMP solution makes particular sense if you are pursuing a multi-cloud strategy, have a high level of complexity in your IT infrastructure, or are looking for ways to automate management and increase efficiency. A CMP solution can help to overcome the challenges of cloud management, control costs and ensure that all security and compliance requirements are met.
Even though many providers advertise cost optimization, implementation and operation can be costly, as additional licensing and operating costs are incurred. Employees need to be trained on the new solution before efficiency can be felt. The effort involved in setting it up should not be underestimated. Whether and which CMP is the best solution must be considered on an individual basis. There is no universal solution or de facto standard. The best choice depends on your individual starting position, coupled with the needs and strategic goals of your company.
Would you like to find out more about the benefits and implementation options of cloud management platforms for your use case? Contact us and we will help you identify the optimal solution for your needs - together we will find the right solution.
The future of networks
The digital era has increased the importance of networks in our daily communication and interaction. In an effort to meet the increasing demands for security, reliability and efficiency, the SCION network protocol is emerging as a promising solution in the field of wide area communication (Internet). In this blog post, we will take a closer look at SCION and understand how it challenges the existing paradigms.
Background: What is SCION?
SCION, which stands for "Scalability, Control, and Isolation On Next-Generation Networks", is an advanced network protocol that aims to overcome the shortcomings of traditional Internet architectures. Developed by researchers at the Swiss Federal Institute of Technology in Zurich (ETH Zurich), SCION offers an innovative solution to challenges such as security, scalability and efficiency.
The functionality of SCION is based on a network of trusted participants and is organized via existing autonomous systems (AS) in independent routing levels, so-called isolation domains (ISD). Each AS requires a corresponding certificate in order to be integrated into an ISD. SCION offers inherent security, as access to a communication network is always explicitly regulated and policies are enforced. SCION traffic is routed along predefined paths, giving users effective control over the path of their data. The multi-path approach ensures that this is reliable even if one path fails, without compromising the path specifications.
Safety as the top priority
An outstanding feature of SCION is its intensive focus on security. In the traditional Internet, threats such as DDoS attacks and routing manipulation are omnipresent. SCION counters these threats by strictly separating the control and data transmission layers. This concept isolates attacks on the control layer, which significantly strengthens the overall resilience of the network.
Trusted paths and improved scalability
SCION introduces the concept of "trusted paths", which are based on predefined routes. Unlike the traditional Internet, where packets often travel unpredictable paths through the network, trusted paths allow precise control over data traffic. This not only improves security, but also the efficiency and scalability of the network, as bottlenecks are avoided and latencies are reduced.
Decentralization of control: a paradigm shift
Another revolutionary aspect of SCION is the decentralization of network control. In the traditional Internet, control over routing and security is centralized by Internet Service Providers (ISPs) and routers. SCION, on the other hand, enables autonomous control at network level, which allows greater flexibility and adaptability. This decentralization not only promises better resistance to attacks, but also promotes innovation in network design.
Outlook for the future
With the ever-growing threat of cyberattacks and the increasing complexity of our digital world, the development of network solutions such as SCION is crucial. The combination of security, scalability and decentralization positions SCION as a promising candidate for the network architecture of the future. While the widespread implementation of SCION is still in its infancy, the first solutions such as the Secure Swiss Finance Network (SSFN) initiated by the Swiss National Bank (SNB) and SIX indicate that we could be witnessing a paradigm shift in the world of networks.
Our consultants will continue to follow the paradigm shift in the world of networks and support our customers in successfully implementing their network projects holistically.
Cloud Network Segmentation
With the possibility of integrating Platform as a Service (PaaS) services into a virtual network, the importance of a secure, scalable and efficiently operable network design also increases. With this blog, we show variants of how Cloud Network Segmentation can look like in the enterprise environment.
Cloud Network Segmentation Principles
A hub-and-spoke network architecture has established itself as best practice in the cloud and is now used in most companies in the enterprise sector. Here, overarching network services such as firewall, connectivity or routing are controlled centrally in a hub network. Peerings are used to connect workload networks (spokes) to the hub, which controls all traffic between different spokes in the hub.
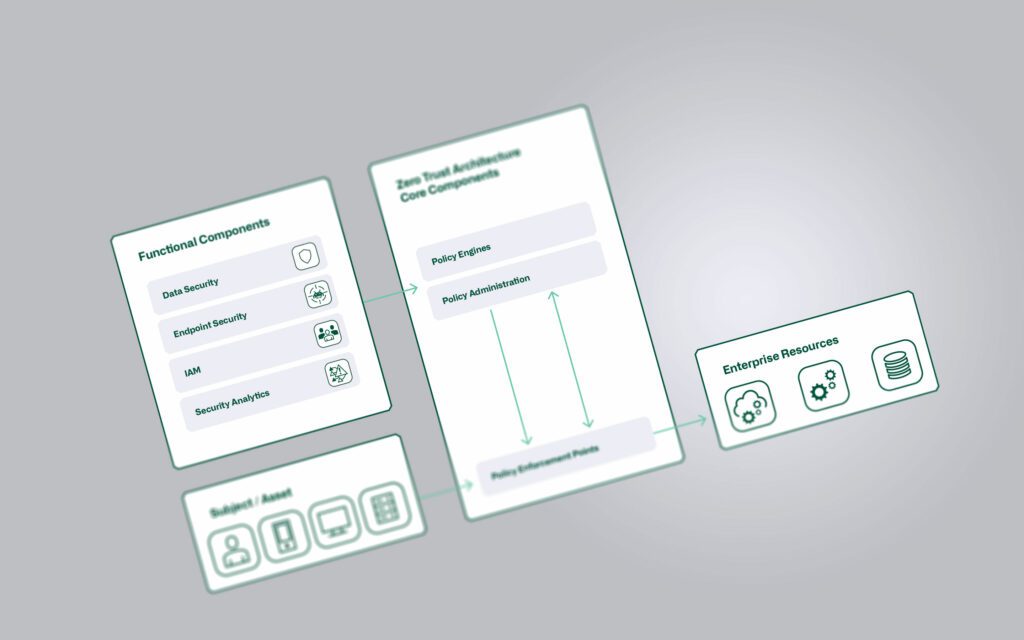
While the path to micro segmentation is very complex on premise, this concept is already used as standard in the cloud. A zero trust approach is increasingly being pursued, which enables much stricter isolation of individual applications. This is also reflected in controls from various best practice security frameworks such as the Microsoft Cloud Security Benchmark (NS-1/NS-2), CIS Controls (3.12, 13.4, 4.4), NIST SP 800-53 (AC-4, SC-2, SC-7) or PCI-DSS (1.1, 1.2, 1.3).
Blog
For supplemental information on Zero Trust, see our dedicated blog post:
Implementation of a Zero Trust Architecture
In the cloud, there are five basic tools that contribute to a functioning network segmentation:
- Virtual networks
VNets (Azure) or VPCs (AWS and Google) can be used to isolate resources, since free communication is only possible within a virtual network by default. However, they can be connected to each other by means of peerings to the hub.
- Subnets
Additional segmentation by subnets is possible within a virtual network. This allows individual application components (e.g. frontends, key vaults or databases) to be isolated from each other and controlled by the firewall via the specific subnet ranges.
- Firewalls
Firewalls can be used to control and inspect traffic that is routed to the hub via peerings. This is done on defined IP addresses or address ranges (L3), but can also be implemented on an elevated layer (L7) using FQDN rules.
- Network Security Groups / Network Access Control Lists / VPC Firewall Rules
Network Security Groups (NSGs, Azure), Network Access Control Lists (ACLs, AWS) or VPC Firewall Rules (GCP) are simplified firewalls that control traffic within a virtual network. These NSGs or ACLs are attached to individual subnets and define the incoming and outgoing traffic based on source/destination, protocol and port.
- Route Tables
By default, outgoing Internet traffic is routed directly from the respective subnet to the Internet. To change this and to inspect or control the traffic in a firewall first, route tables and user defined routes (UDRs) can be used and linked to subnets.
However, the question now arises as to how the aforementioned tools can be combined in the best possible way in order to achieve the goal of efficient, secure and scalable segmentation.
For better readability, Microsoft Azure terminology is used in the following sections, but the principle applies equally to AWS and GCP.
Variant 1 - Segmentation of virtual networks
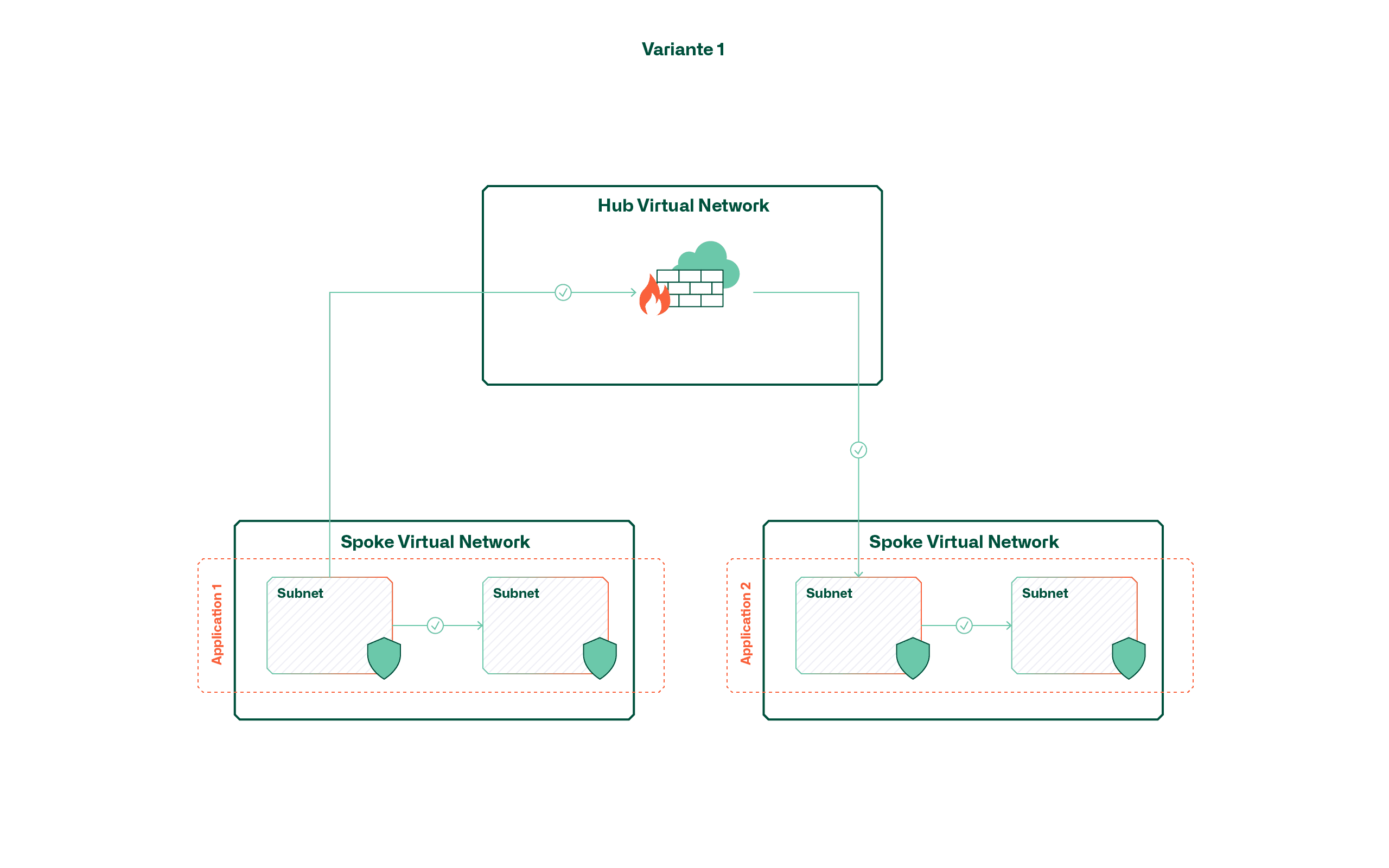
This variant follows the principle that each application or service is hosted in a dedicated virtual network. The result is that a virtual shell is created around the application by default and communication within it is handled via subnets and network security groups.
The advantage of this variant lies primarily in the low complexity and the continuous isolation of applications, since the application boundaries are enforced directly by means of virtual networks. However, it should be noted that due to the limited number of peerings (currently 500 per hub in Azure), the maximum number of applications is limited accordingly. This limitation is even more significant if separate environments (dev, test, prod) are required for each application.
Another factor to consider in this variant is cost. The number of VNets is not a direct cost factor, but all cross-VNet traffic is charged. One consideration may therefore be that applications that exchange a lot of data frequently are clustered in the same VNet.
Variant 2 - Segmentation by means of subnets
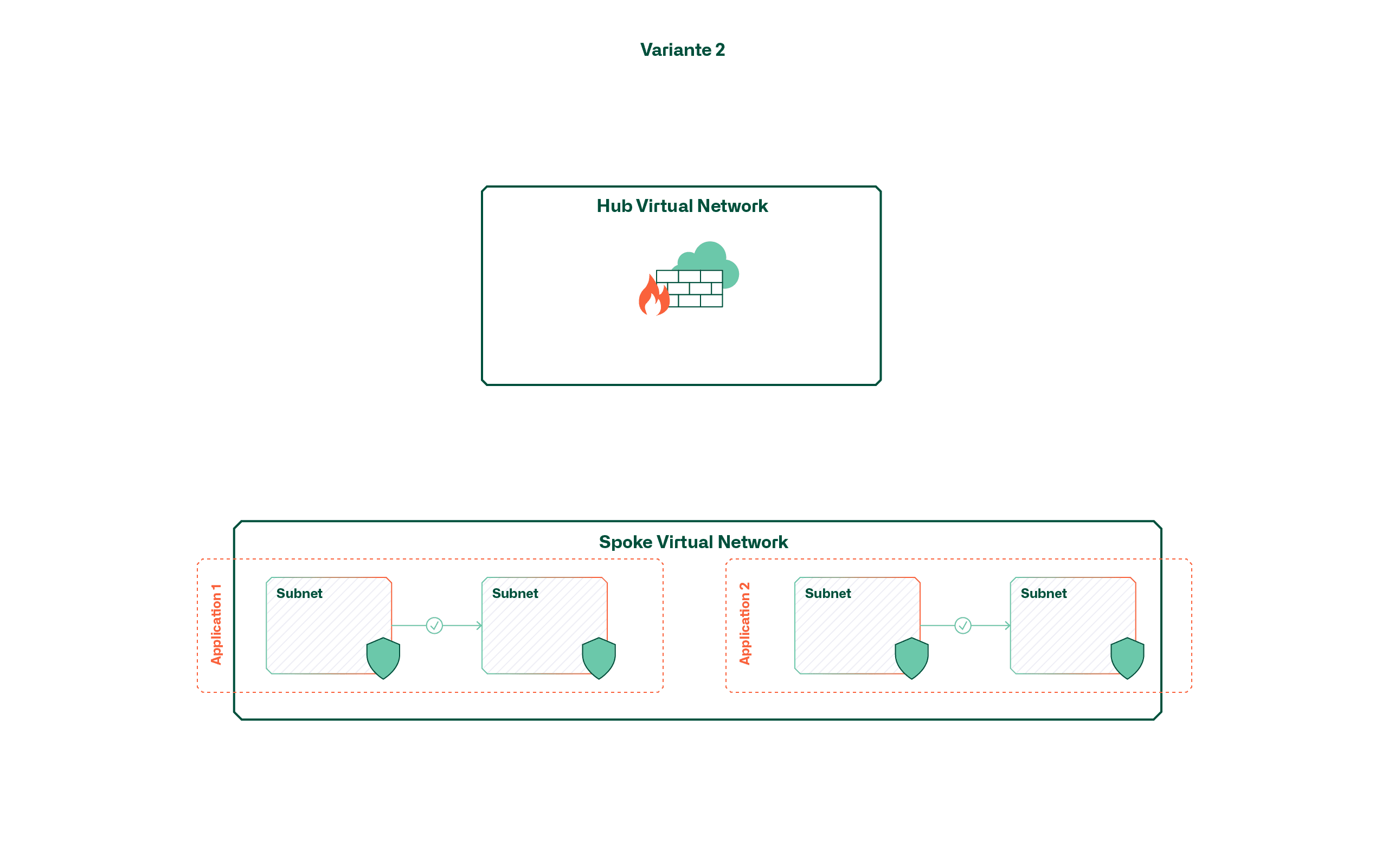
Instead of application-specific virtual networks, this variant uses larger, shared networks (e.g. per environment). The separation of applications within these virtual networks takes place (if at all desired) via subnets and network security groups. This means that open communication within an environment or zone is possible by default.
This variant has the advantage of being easy to use, provided that open, cross-application traffic is desired. If this is not the case, the increasing number of applications leads to a confusing landscape of subnets and network security groups. Above all, the fact that there is currently no overarching view for managing subnets or NSGs makes it difficult to manage rules for additional applications.
Variant 3 - Segmentation by means of route tables and firewall
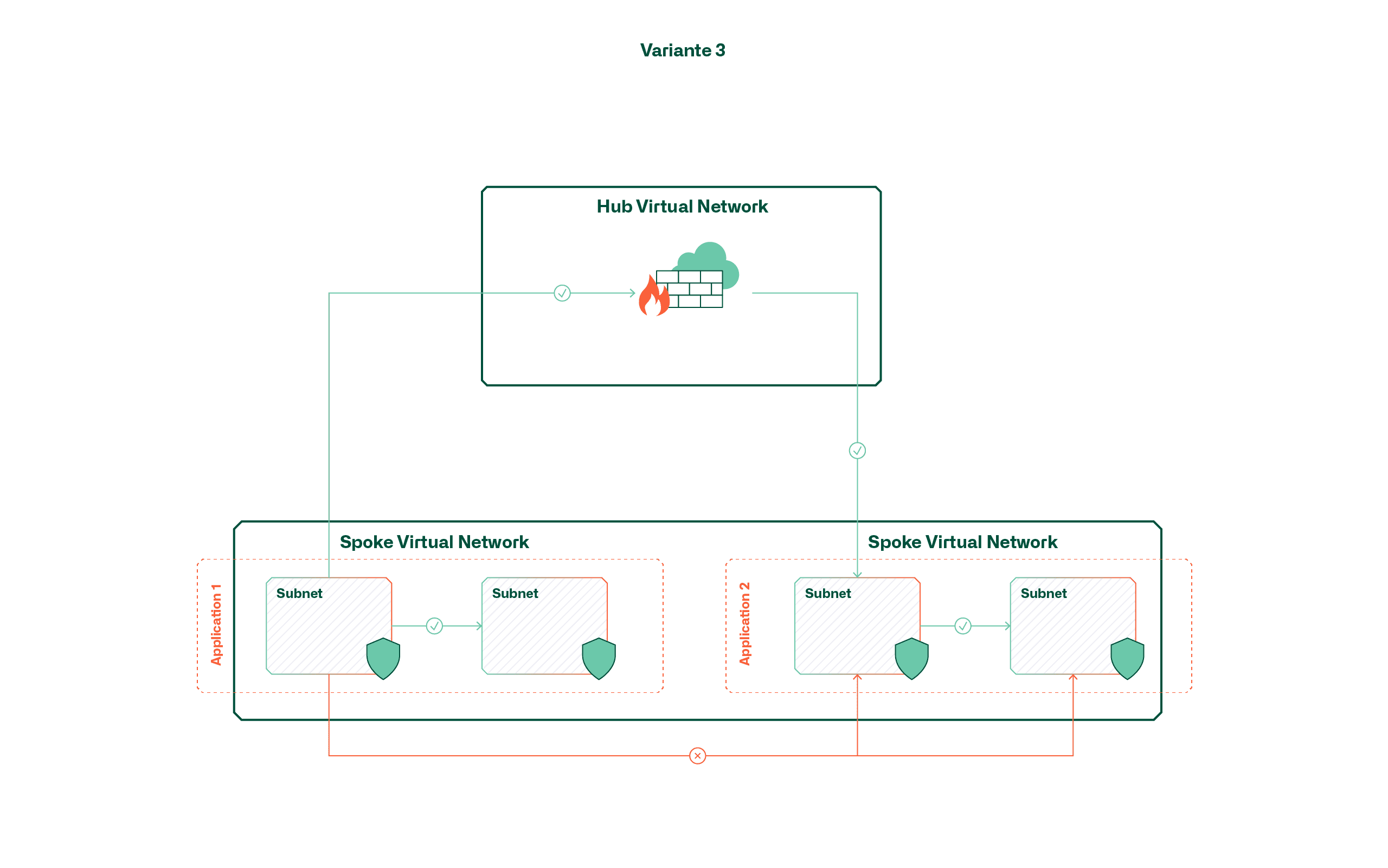
This variant achieves a mix between the first two variants by placing applications in a large, shared network, but always routing traffic to the central firewall in the hub and controlling it there. This is made possible with multiple user-defined routes (UDRs) that override the default routes within the virtual network.
Although this variant could give the impression that the advantages of the previously mentioned variants can be combined, handling also becomes complex here as the application volume increases. The reason for this is that the default routes can only be overridden by UDRs if they are equally specific or more specific. A default route (0.0.0.0/0) does not have the desired effect for internal traffic in this case; instead, an additional route would also have to be created for each subnet (max. 400 per Route Table).
Conclusion / Recommendation
In order to comply with the zero trust approach, we recommend variant 1 and thus strict network separation of applications with the aid of dedicated virtual networks. Microsoft has also indirectly anchored this approach in its cloud adoption framework and stipulates that applications are to be placed in dedicated subscriptions as a matter of principle (subscription democratization), which consequently also leads to dedicated virtual networks.
The reason for this recommendation lies mainly in the scalability required in the medium term. Although a shared virtual network may seem sensible at the beginning with a manageable cloud portfolio, the operating effort and complexity increase exponentially as the number of applications increases. Although an architecture change is also possible retrospectively, it means redeploying all components within the virtual network.
Basically, we recommend not to underestimate the network design in a cloud project and to deal with it already at the beginning. After all, the network, together with identity management and governance mechanisms (policies, RBAC, etc.), is one of the cornerstones on which the applications are built.
atrete IT consultants are your one-stop shop for specialized cloud solutions. At a time when the technology landscape is constantly changing, we have bundled our more than 25 years of IT infrastructure expertise in the areas of cloud networking, cloud security, cloud automation and cloud strategy. This is how we develop tailor-made solutions for your challenges.
Cloud service models - which skills are needed and to what extent?
The transformation of an application to a cloud provider not only requires new know-how, but also always requires additional resources - relief only comes after consistent dismantling of existing infrastructures.
What does the Cloud Journey mean for internal IT skills?
Cloud computing, or "the cloud" for short, as it is colloquially known today, is currently experiencing immense hype. Great promises are being made from all sides, expectations are being stoked, but concerns are also being expressed and caution is being urged. This is a typical situation that occurs time and again with disruptive technologies. For IT managers, this means that, together with their business managers, they have to deal with the new possibilities, risks and consequences and define their own path to the cloud.
One facet of the cloud journey which is underestimated, especially at the beginning, and often receives too little attention, is the question: What skills and what know-how does a company need if it produces its IT services mainly with cloud computing services? It is important not to be blinded by the widespread marketing promise, which suggests that cloud services can simply be consumed without any effort on your part.
In the real world, IT applications are rarely isolated systems, but almost always part of a network with interfaces to other applications and peripheral systems. From the user's point of view, the user experience is expected to be as uniform as possible. The integration of the various applications into a meaningful IT landscape is special for each company and individually adapted and optimized for the respective requirements.
The range of service models in use is multifaceted and can be roughly divided into the following generally known categories:
- Software as a Service (SaaS)
- Platform as a Service (PaaS)
- Infrastructure as a Service (IaaS)
- On Premises
The trick now is to develop and operate an IT landscape that is as uniform, consistent, and cost-optimized as possible from all the available options. As already mentioned, attention must be paid to the aspect of the skills and know-how required for each service model.
Know-how, skills and service models
Depending on the service model, the required skills shift from highly technical to more service-oriented organizational know-how. In addition to the shift in skills, however, the effort required to perform the activities must also be taken into account. In the following graphic, we have compared relevant IT skills with the various service models. The evaluation is based on the required depth of knowledge, the complexity of the contexts, and the time and resources required.

Operation
In-house required operating skills are reduced linearly with the reduction of the vertical integration of the service models, as more and more infrastructure components are outsourced to the provider. Regular maintenance of hardware, operating systems and databases is thus gradually eliminated as the service model increases.
Engineering
A similar picture emerges with regard to engineering. However, the gradation of the required skills is significantly steeper than in operation. If new services are created or existing ones are further developed, the effort required for PaaS or IaaS solutions is significantly higher than for SaaS, since significantly more interfaces and compatibilities have to be taken into account.
Architecture
In the area of architecture, internal skills can be saved primarily by using SaaS services. The conceptual effort required to integrate IaaS or PaaS services into the IT landscape is only partially less than designing new on-prem services. Here, too, issues such as compatibility and interfaces to existing services play a greater role.
Security
Security in the IT landscape is equally relevant in all service models. However, the focus of security is shifting vertically from technical skills, such as hardening the system, to organizational efforts, such as checking data locations. Internal efforts can therefore only be reduced by purchasing SaaS services, since all work relating to the underlying infrastructure is taken over by the provider.
Identity
In the area of identity management, the demands on the internally required skills increase when services are outsourced from on-prem to an "as-a-service" model until all underlying infrastructure components are left to the provider. PaaS and IaaS thus offer the disadvantages of on-prem and SaaS in identity management without taking over their advantages. Additional identity management comes into play, which must be integrated into the existing system or managed as a supplement. In addition to access to the application, authorizations must also be set for the underlying infrastructure components.
Data management
The relevant know-how for correct data storage differs greatly depending on the service model used. While a SaaS solution requires more thought in advance regarding data location and access, an on-prem approach requires more technical skills in the area of backup and availability. IaaS and PaaS services have higher requirements here, as the know-how for both topics must be readily available.
Cost management
An overview of the costs is required in all service models. However, the effort and knowledge required to create such an overview differs again between the service models. PaaS and SaaS services have particularly high requirements. Services such as an SQL database can be obtained in different functionalities, availability levels, scaling levels and sizes. In addition to this technical diversity, further distinctions can also be made in the billing models. The operating costs can thus quickly rise to an unexpected level and, depending on the configuration, only become transparently apparent at the end of the month. SaaS services with their user or device licenses are much simpler. Since on-prem is not based on the pay-as-you-go principle, it is much more complex to determine the costs of individual components. However, errors in the calculation do not result in an unexpectedly high bill.
Provider Management
Provider management involves the art of being able to react quickly to changes to a related service or application by the provider in order to be able to counteract possible negative effects in a timely manner. The more control is relinquished over one's own infrastructure, the more effort must be expended in this regard. In a worst-case scenario, for example, an application on an IaaS VM is migrated much faster than the same application in a SaaS model. Backup, disaster recovery or even availability are increasingly implemented only contractually and not via configurations of the engineer as the vertical integration decreases.
Conclusion
Under the influence of the increasing use of cloud computing, an IT landscape is based on an ever greater variety of service models. In principle, it can be assumed that the more diverse the service models used, the greater the breadth of expertise required.
Mastering these different service models therefore does not necessarily require new skills, but often adaptations of existing know-how. Although, for example, the operating effort tends to decrease with the migration from on-premises to the cloud, a company should still deal with new topics such as IaC or DevOps.
Blog
For supplementary information on CI/CD and IaC, please see our dedicated blog post
CI/CD and IaC
However, new tasks generated by a migration and the associated changes in the required know-how are to be understood as additional effort in all cases. This is the case until the existing environment is actively dismantled. The choice of service model has no influence here.
The cloud strategy must therefore carefully determine which service models are to be used in order to deduce the extent to which the skills available today will be needed in the future. Each company must therefore analyze in detail which know-how should be newly built up, which should no longer be maintained, and which should be brought in from outside if necessary.
As an independent consulting firm, atrete is constantly dealing with problems related to IT and the cloud for various customers. On the one hand, we can support companies in the context of their cloud journey in analyzing and defining the necessary skills. On the other hand, we also provide experts with specific skills for external support of internal teams.
atrete receives further reinforcement
Last month, the IT consulting company atrete received further reinforcement. Our new colleague expands the area cloud.

Marco Jenny joined atrete on 01.09.2022 as a consultant in the cloud practice area. He has many years of professional experience in IT services in the areas of system engineering, application management and cloud. His university degree in business informatics FHNW together with a certification as requirements engineer (IREB Foundation) complete his profile.
Prior to atrete, Marco Jenny worked as an Application System Engineer in the Microsoft Cloud with a strong focus on the design and implementation of Modern Workplace. Due to the technological change in the past years, he gained insight and experience in different types of Microsoft Cloud projects.
Complementing this experience, Marco is currently in further education to become a "Microsoft Azure Solution Architect Expert".
Microsegmentation: Where are we today?
What is microsegmentation ?
Microsegmentation has gained importance in the course of the virtualization of IT and network infrastructures in the data center, the growth due to general digitization, and the associated dynamics. The term microsegmentation is used to describe security technologies and products that permit fine-grained assignment of security policies to individual servers, applications and workloads in the data center. This allows security models and their application to be applied deep within the data center infrastructures and topologies and not just at larger network and zone perimeters. This has become very important as in modern digitized environments, much of the traffic between applications and servers occurs within the data center rather than primarily from the outside in or vice versa.
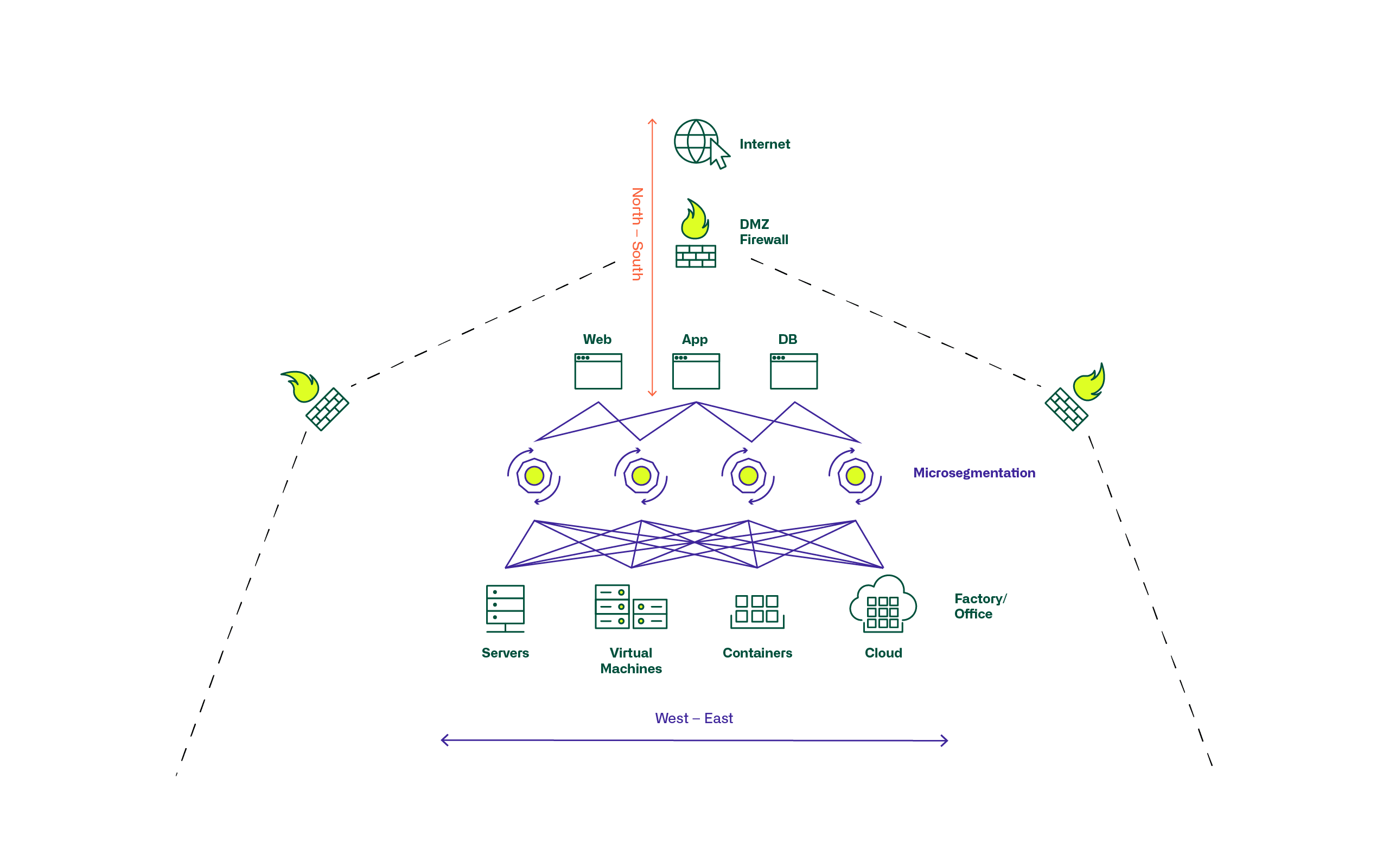
Microsegmentation has become established to varying degrees.
In classic infrastructures, smaller network segments are formed with increased network virtualization and automation. Generally valid firewall rules, applied to entire zones, are being replaced by pin-holing with individual rules per server/application.
Server and network infrastructure has changed from less flexible, individualized and manual perimeter protection to partially automated zones, types and classes of servers to micro-segmented, highly structured, standardized and automated systems for this purpose.

This also places different demands on the management and maintenance of security policies and firewall rule sets in particular, as many places do not have one or the other environment in pure form, but rather transitions and interfaces from old to new and software defined to classic infrastructure must be operated and ensured.
Among the available products and technologies, a distinction must be made between
- Network-based
- Hypervisor integrated or cloud-native
- Server OS/workload integrated as a separate application
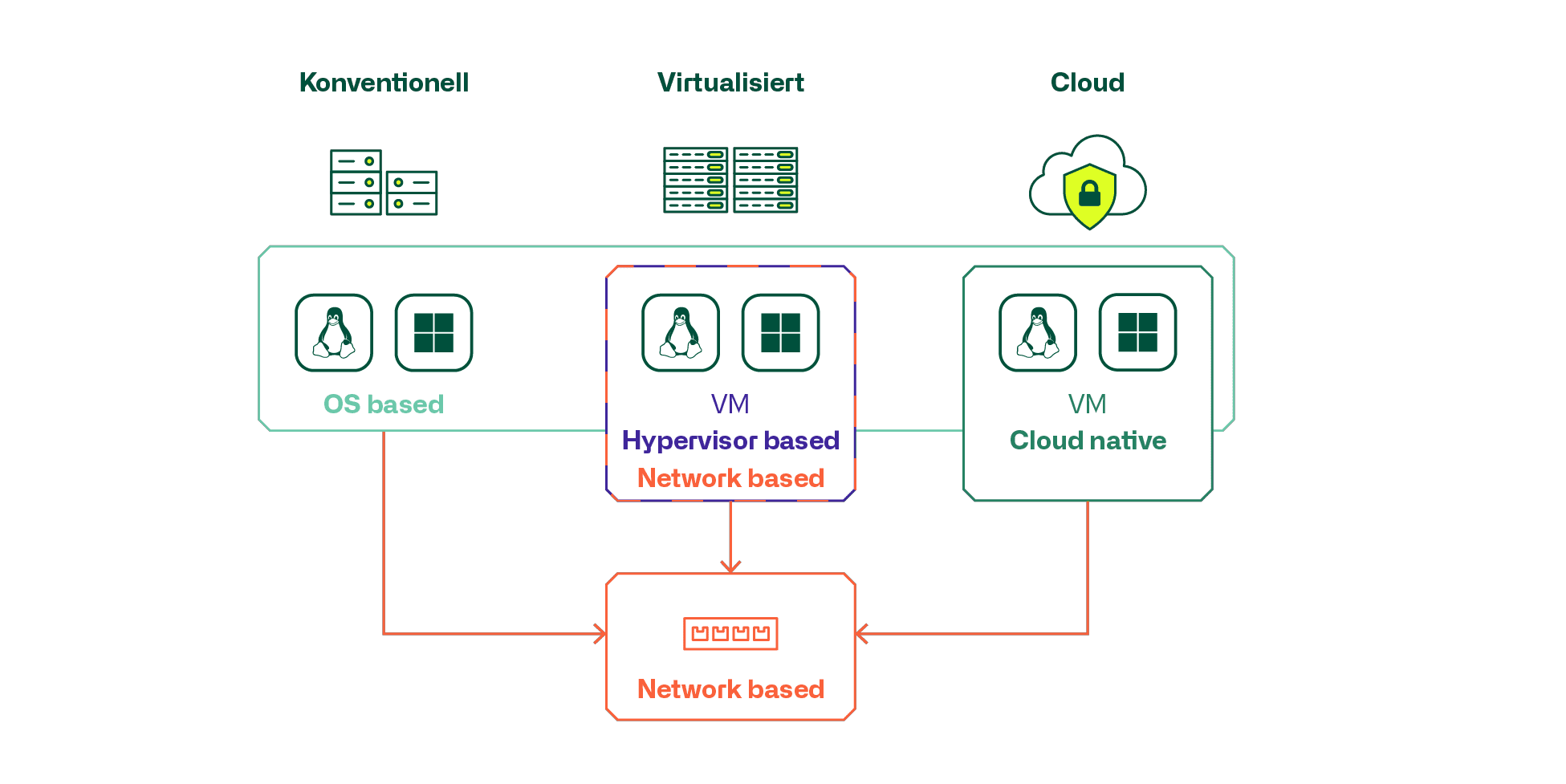
The most common use cases can also be grouped somewhat.
Conventional server infrastructures primarily use products with network-based or OS-based microsegmentation. It is important to consider the extent to which older servers and OS versions of OS-based products are supported at all.
For classic virtualized and private cloud infrastructures, the hypervisor-based, and virtualization-integrated micro-segmentation solution is often used, and for public clouds, the cloud-native solution offered by the cloud provider.
Particularly in larger environments, it is apparent that combinations of technologies and products are frequently used and requirements are placed on cross-product management and administration of security policies and FW rules and objects. These requirements increase with the degree of virtualization, micro-segmentation and highly dynamic automated cloud and container infrastructures. It becomes a challenge to ensure dynamic and automated creation of instances and objects, as well as their deletion in end-to-end configurations in an automated manner. Today's developers are accustomed to creating and deleting entire application environments in an automated fashion, and the infrastructure must keep pace to ensure that the appropriate security policies and rules match the effective instantiations that exist.
Our consultants will be happy to support you to make your microsegmentation project a complete success.
CI/CD and IaC
The integration, delivery and deployment of code are state of the art today, but they involve various non-technical challenges that need to be overcome.
In this blog post, we introduce Continuous Integration, Continuous Delivery and Continuous Deployment (CI/CD) and show what added value can be gained by using them. The article also explains what role CI/CD plays in the Infrastructure as Code (IaC) approach and which deployment variants exist on-prem and in the cloud.
Introduction - Concept CI/CD
In the time before CI/CD, the integration of changes to a digital product rarely went smoothly. The holistic consideration and testing of all dependencies between new and existing code proved to be difficult, and often time-consuming reworking of the code was necessary before it could finally be integrated into the productive system.
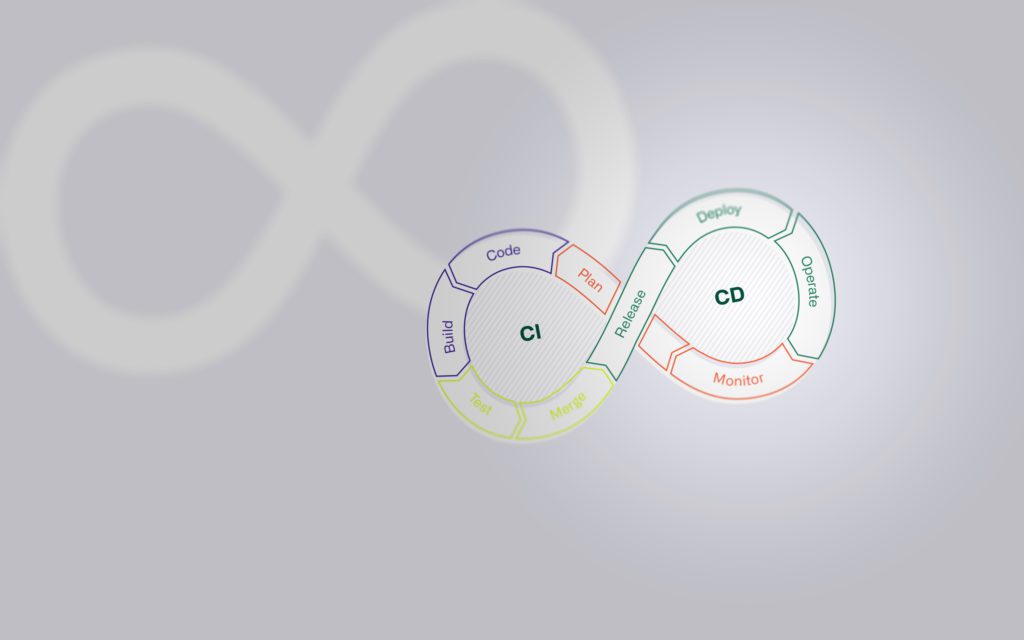
The processes, techniques and tools of the CI/CD concept create a premise that enables the continuous and immediate integration of new or changed code into the existing solution. Using CI/CD, applications can be continuously monitored in an automated manner throughout their entire life cycle (Software Development Life Cycle, or SDLC for short), from the integration phase, through the test phase, to the delivery and deployment of the application. The practices used in CI/CD are collectively referred to as the "CI/CD pipeline." The development and operations teams working according to the DevOps approach are thus supported.
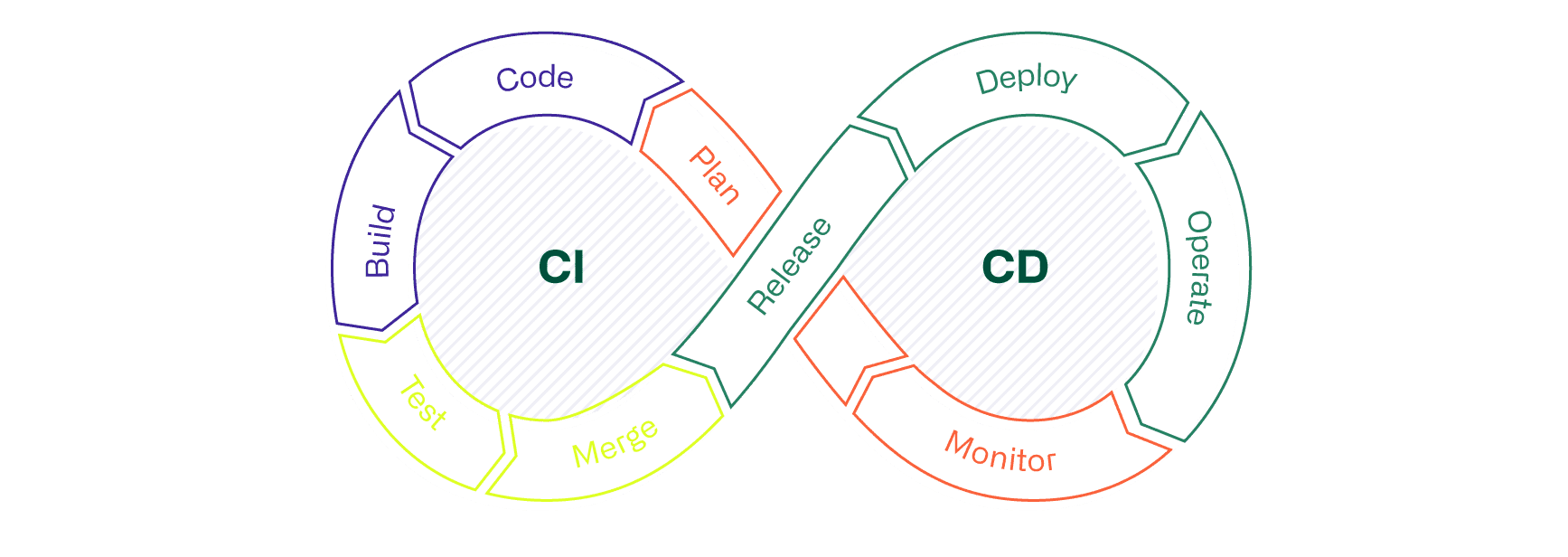
CI/CD in the use of IaC
The use of a CI/CD pipeline is also of central importance in the Infrastructure as Code (IaC) approach, among others. In the context of IaC, in addition to the automation logic, various properties of hardware- and software-based infrastructure components from the cloud or on-prem are stored in a repository. Such properties stored in files do not have to be 1:1 copies of current configurations. Parameterized files, for example in YAML notation, are often preferred. The big advantage is that the information in the configuration files in the repository, despite a high degree of automation, can still be read (human-readable) and understood by a person. Whether human-readable or not, in any case the CI/CD pipeline is the prerequisite for an automated, transparent and continuous validation of configuration files and the subsequent integration of changes in the infrastructure.
Continuous Integration (CI)
CI consists of the automated process that ensures the continuous integration of customizations to an application. Continuous Integration supports developers in regularly making and publishing changes to the code. Automated testing processes such as code analysis or unit tests (code tests) ensure that edited branches in the code repository can be merged so that the application continues to function. The branch of a repository is part of the development process and can be viewed as a branch referencing the existing, validated code. If developers need to make changes to the existing code, a new branch is first created in which the change or enhancement is made. A merge is then performed to merge the final code changes with the existing code in the repository.
In summary, the successful CI contains the automated
- Creating the customized application (build)
- as well as their testing (test)
- and merging the changed code into a code repository such as GitHub (Merge).
Unless otherwise configured, a merge is only successful when all defined processes (jobs) within the "CI/CD pipeline" have been successfully run through.
Continuous Delivery (CD)
The abbreviation "CD" has two meanings. On the one hand Continuous Delivery, on the other Continuous Deployment. These similar concepts are often used synonymously. Within the framework of both concepts, the automated processes that follow CI are designed in the pipeline. In some cases, the terms Continuous Delivery and Continuous Deployment are used to specify the characteristics of automation. What this means is explained in this blog in the section Continuous Deployment. A CI integrated into the pipeline is the prerequisite for an efficient CD process. Continuous Delivery enables automated deployment of applications to one or more environments after successful code validation by the CI. Developers typically use environments for the build, test and deploy phases. Possible processes (jobs) from the different phases are many.
For example, this can be
- creating a build of the application,
- managing and schema validation of environment variables that define an entire infrastructure or individual component of it,
- testing and resetting an environment or specific components of it if the tests fail
- and many other activities.
Successfully passing through all Continuous Delivery phases allows the operations team to quickly and easily deploy a validated application or infrastructure configuration to production.
Continuous Deployment (CD)
Continuous Deployment is an extension of Continuous Delivery. Continuous Deployment enables the automation of releases of customizations of an app or even infrastructure configuration files. Continuous Deployment thus allows a seamless and fast integration of code adaptations into a productive environment, sometimes in just a few minutes. This is made possible by sophisticated and extensive automatic tests within the various phases of the CI/CD pipeline. However, fully automated deployment does not always make sense. If the automatic testing elements of the pipeline cannot cover compliance with all guidelines and thus ensure governance due to certain circumstances, deployment must be done manually. At least until the necessary premise has been established. This can be enabled by means of improvements such as standardization, adapting existing processes (if possible), resolving external dependencies or taking them into account by means of access via an interface, etc.
CD/CD and IaC deployment variants
In the cloud as well as on-prem, there are various use cases that are suitable for CI/CD. For example, the DevOps team can distribute serverless or fast, automated code updates using container technology. Depending on the target architecture and the scope of the adaptation, different distribution approaches are available. The following list contains the three best-known, which can be used in the cloud and on-prem.
| CI/CD - Distribution approaches |
| Blue-Green deployment provides for development on parallel dedicated infrastructures. The production environment (blue) contains the latest, working version of applications or adjustments to the infrastructure. In the staging layer (green), the customized applications or the infrastructure modified by customized configuration files (IaC) are extensively tested for their functions and performance. This deployment approach enables efficient implementation of changes, but can be cost-intensive, depending on the complexity of the production environment. |
| Rolling deployment is used to distribute adjustments incrementally. This reduces the risk of failures and enables simple rollbacks to the previously functioning state in the event of problems. Consequently, as a prerequisite for rolling deployment, the services must be compatible with the old and new versions. Depending on the case, these are application versions or, in the case of IaC, infrastructure configuration files. |
| Side-by-side deployment is similar to Blue-Green deployment. In contrast to Blue-Green, the changes are not distributed across two environments, but are made available directly to a selected user group in production. Once the user group confirms the functionality and performance previously tested in the CI/CD pipeline, the updates can be deployed to all other users. This allows developers to run different versions in parallel, just as with rolling deployment, and additionally to gather real user feedback without high risk of downtime. |
A recommendation of the deployment variant is situational and depends on the product to be deployed and the infrastructure.
Below we describe an exemplary excerpt of solutions for CI/CD and IaC projects:
| Terraform | Project by HashiCorp, which is very flexible to use and compatible with well-known cloud providers such as AWS, Azure, GCP and OpenStack. |
| Ansible | Project from Red Hat, which is an orchestration and configuration tool that enables the automation of repetitive and complex processes using playbooks. |
| AWS CloudFormation | IaC service that enables managing, scaling, and automating AWS resources using templates within the AWS environment. |
| Azure Resource Manager | IaC tool of the Azure environment, which enables, among other things, the deployment and management of Azure resources using ARM templates. |
| Google Cloud Deployment Manager | Infrastructure deployment service from Google that enables the creation, provisioning and configuration of GCP resources using templates and code. |
| Chief | Well-known IaC tool that can be used in AWS, Azure and GCP together with Terraform due to its flexible deployment options and provisioning of its own API. |
| Puppet | Similar tool to Chef, which is also commonly used for monitoring defined and provisioned IaC properties and automatically correcting deviations from the target state. |
| Vagrant | Another solution from HashiCorp, which enables rapid creation of development environments and is aimed at smaller environments with a small number of VMs. |
In the hybrid cloud environment, the in-house CI/CD and IaC solutions of cloud platforms such as AWS, GCP and Azure are usually not sufficient. For example, Terraform and Ansible can be a suitable solution for IaC due to their high flexibility and compatibility, especially in multicloud environments.
Blog
Multicloud
Find out what else there is to consider regarding multicloud scenarios in our blog post about multicloud.
Implementation - opportunity and challenges
Various opportunities can be profited from the implementation of CI/CD. The most important opportunities are summarized in the following list as examples:
| Opportunities |
| Shorter time to production and fast feedback - Automated testing and validation in the CI/CD pipeline eliminates tedious, manual and therefore time-consuming steps. |
| More robust releases & earlier detection of errors (bugs) - Extensive testing of code and functions. Simple errors are avoided. |
| High visibility (transparency) - Using the CI/CD pipeline, individual test results can be checked in detail. If defects or errors are discovered in new code, this is shown transparently. |
| Cost reduction - Reduction of costs based on reduction of simple errors. In the long term, the use of CI/CD is less error-prone due to automation and thus sustainably cheaper. |
| Increased customer satisfaction - The consistent and reliable development process results in more reliable releases, updates, and bug fixes. This increases customer satisfaction. |
However, various challenges must also be mastered for the implementation and operation of CI/CD. One of the biggest and most important is standardization in the company's own infrastructure. It determines the degree of automation to a large extent. In general, it can be assumed that a homogeneous infrastructure enables a high and cost-efficient degree of automation. Heterogeneous environments should be standardized as far as possible if high automation is the goal. It should be noted that introducing or merely increasing standardization can be a major undertaking in itself. Other challenges that need to be mastered are:
| Challenges |
| Adaptations in the corporate culture - CI/CD is used and lived in the context of agile corporate cultures and approaches, especially DevOps. Consequently, teams must be comfortable and familiar with the iterative, agile way of working. |
| Expertise - Correct implementation of CI/CD requires a lot of expertise and experience. Not only in the technical area, but also in the organizational area. |
| Reactive Resource Management - To ensure performance across all of CI/CD's automated processes even under increased demand, resource management should be monitored and responsive. |
| Initial development costs - The initial expenses for a development environment, the build-up of know-how, conceptual design, standardization and process adaptation can be high, but are justified by the added value gained from CI/CD. |
| Microservice Environment - To ensure high scalability, a microservice architecture is ideally built. Those responsible for the architecture must be aware of the accompanying increase in complexity and dependencies and the requirement for their administration. |
Our assessment
The setup and design of CI/CD depends on the setup in one's own development and infrastructure environment. In our estimation, there is no ready-made concept for the CI/CD pipeline. Which tests and validations are implemented in Continuous Integration, which phases are implemented in Continuous Delivery and how the distribution is carried out in the context of CD must be individually determined and conceptualized despite various best practice approaches. At least at the beginning, the necessary know-how in the various specialist areas such as software development, quality assurance and, especially in the IaC approach, the existing expertise in the various infrastructure areas is often neglected.
The IaC approach offers a visionary solution that has already been tested in practice and enables infrastructure and its services to be designed adaptively, easily maintainable and securely both on-prem and in the cloud. CI/CD is a core element that enables the correct and transparent mapping of configurations from a central repository to infrastructure components. As explained in this blog post, the use of CI/CD is worthwhile. The cost-effective and short implementation times of changes into production, more robust releases and the resulting increased customer satisfaction are just a few of the many opportunities CI/CD offers. In order to take advantage of these opportunities, the implementation as well as the operation of CI/CD must be successfully managed. Challenges such as a high level of standardization in the IT landscape, possible adaptation to an agile organizational form, and the procurement of expertise must be mastered.
We are happy to support you in analyzing where you stand in terms of requirements for the use of CI/CD (degree of standardization, form of organization, etc.) and in evaluating and designing possible CI/CD solutions in the cloud.
Our years of experience in the essential disciplines for your individual Cloud Journey. With our support, you can master the hot topics such as network, organization, availability, automation, CI/CD, IaC, governance/compliance, security & cost management.
Cloud network integration
No matter which cloud strategy is to be implemented, it makes sense to connect the local data centre with the cloud, as the path to the cloud corresponds to a step-by-step procedure. There are always services in the local data centre that require access from the cloud. For example, directory and identity services, or access to databases and DDI integration.
Cloud connection
However, the way in which the connection is realised depends on the required quality. Depending on the use case, the following questions must be asked and answered in advance.
Topic
Required quality
Question
- What quality (availability, loss, delay jitter) of connection is required for my use case?
- Do I need a quality guarantee from the service provider?
Connection variant
- Can the required quality be achieved using IPSec VPN, or is a direct connection (e.g. Express Route) required?
- Can I integrate the DC connection into an existing SD-WAN?
It should be noted that in the cloud for IaaS and PaaS, virtual networks are primarily created with private IP addresses (RFC 1918), which are then routed via the DC cloud connection. SaaS services, which include the cloud portal, are addressed with public IP addresses and are accessed via the internet access that is also used for surfing the internet.
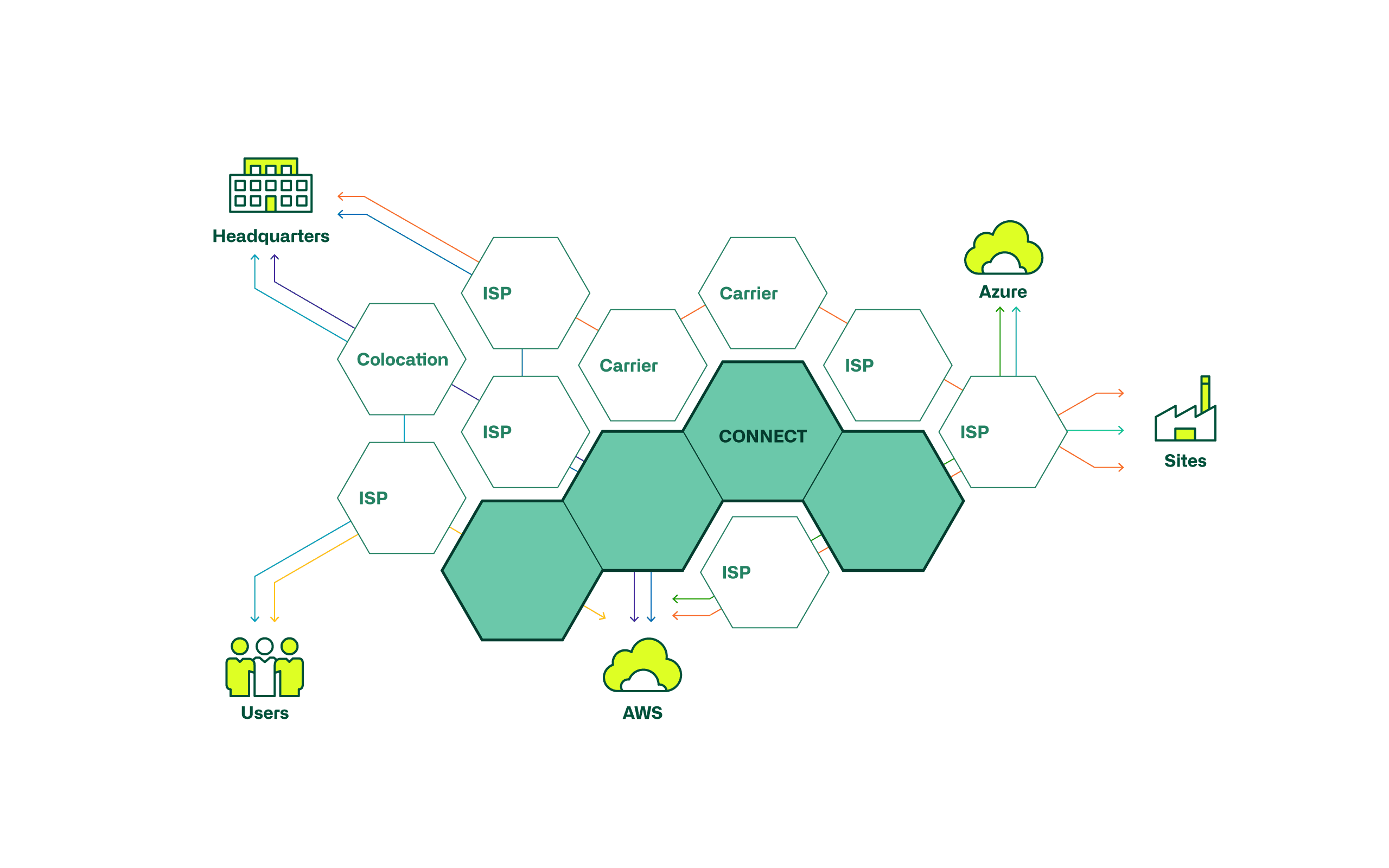
These graphics show the possibilities of connecting a public cloud to the local DC.
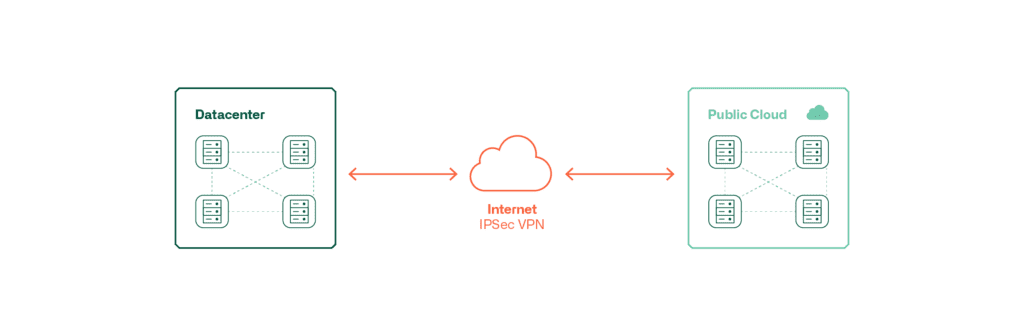
This type of connection is inexpensive and relatively quick to realise. However, this type of connection is not suitable for all quality requirements.
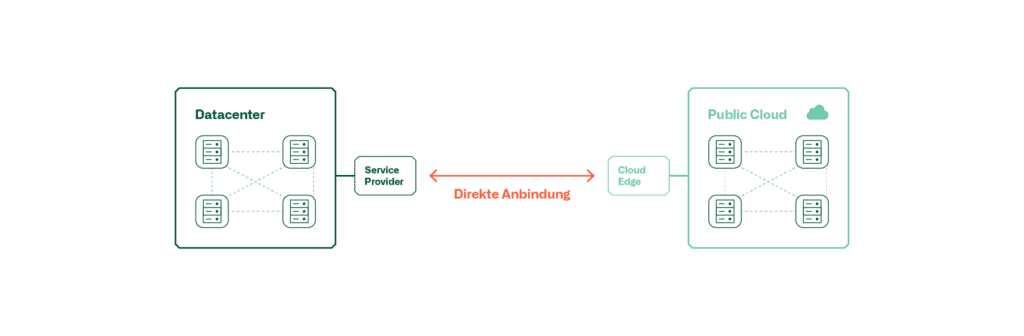
For high quality requirements, a direct connection of the cloud to the local data centre is suitable. Such a connection is made via a service provider who offers these services in the respective country. Here, too, the connection is usually encrypted.
Another variant is SD-WAN, which is usually accompanied by the connection of the users. SD-WAN represents a platform on which various IPsec VPNs with different topologies and transport networks can be realised and centrally managed. Both the IPsec VPN variant and the direct connection can be realised with SD-WAN or, in the case of the direct connection, integrated as a transport.
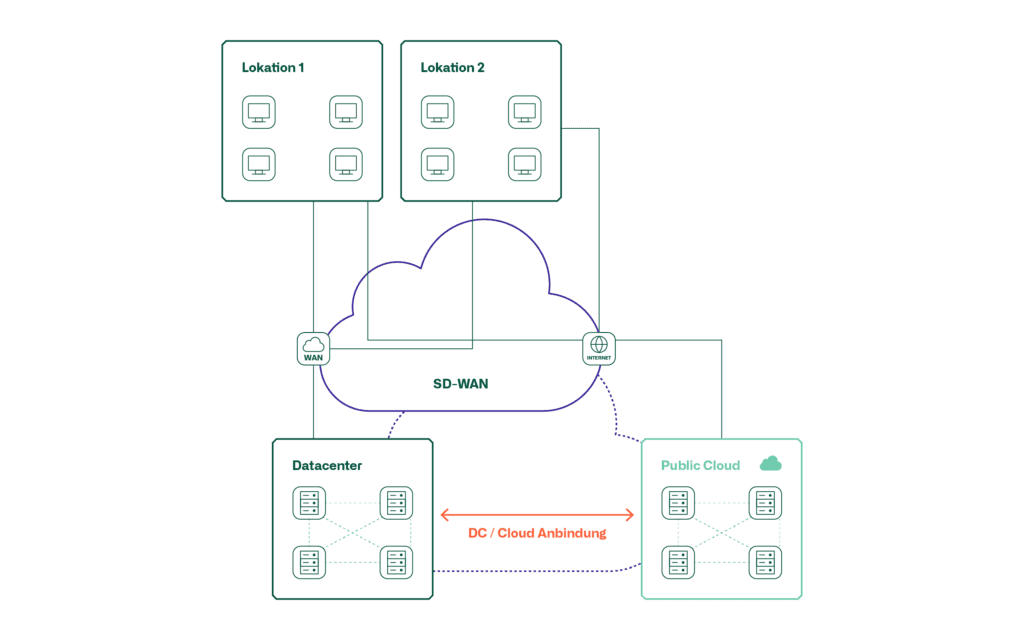
The following table shows which connection variants are suitable for the different use cases.
Variant
Internet IPsec VPN
Recommendation
This type of connection is sufficient for basic needs, unless a guarantee is required from the service provider. It is recommended to realise the connection by means of a TIER 2 internet provider.
Direct connection
Suitable for all use cases and quality requirements. Since this variant also incurs higher costs and is more complex to implement, it should not be considered for use cases that are of a temporary nature.
SD-WAN
If SD-WAN already exists for the connection of the users, it is advisable to use SD-WAN for the DC connection as well, since, as already mentioned, the direct connection is usually encrypted as well.
Cloud Networking
In addition to the connection to the local DC, the question arises as to what functional requirements are placed on cloud networking. On the one hand, this involves network components such as routers, VPN gateways and load balancers, as well as the question of whether a fabric technology used locally in the DC should be extended into the cloud.
Topic
Network components
Question
- What are my functional requirements for the cloud network components?
- Do the cloud native network components meet these requirements or do I need to deploy virtual appliances of network components in the cloud?
DC Fabric Integration
- Should the fabric technology used in the local DC be extended to the cloud? (e.g. Cisco ACI or VMware NSX)
The question regarding network components in the cloud can be answered as follows from a functional point of view.
Variant
Cloud-native
Recommendation
Wherever possible, network components from the cloud provider, so-called cloud-native components, should be used. These are usually sufficient for the standard Layer 2 and Layer 3 functions.
Virtual appliances
If the cloud-native components do not support certain functions, virtual appliances are usually used. This is especially the case for load balancers, VPN gateways and transitions from legacy networking to SDN networking (ACI or NSX).
Whether a DC fabric should be extended into the cloud depends on which cloud strategy is being pursued. If the cloud is operated in hybrid mode for a longer period of time and the network segmentation in the cloud is to be managed with the same tools, then it makes sense to extend the local DC fabric into the cloud. However, if the cloud is used temporarily, such an extension makes little sense. In order to extend the local DC fabric into the cloud, "Cisco Cloud ACI" must be implemented and activated on the cloud side in the case of Cisco ACI and "VMware NSX Cloud" in the case of VMware NSX. These are available in the corresponding cloud stores.
Our consultants have built up and developed the necessary know-how in countless cloud projects from conceptual design to implementation. We support our customers to successfully implement their cloud projects holistically, i.e. beyond the network level.
Multicloud - Does it really make sense?
In this blog, we will look at what multicloud means, for which organisations it really adds value and what needs to be done for a successful implementation.
What is Multicloud?
What exactly do we, as atrete Cloud Consultants, mean by multicloud? If services are obtained from several cloud providers (e.g. Microsoft Azure, Google Cloud Platform (GCP), Amazon Web Services (AWS), or smaller providers), we speak of a multicloud scenario. The deployment model (public, private) or the service model (IaaS, PaaS, SaaS) is irrelevant here. We assume that today almost every organisation - consciously or unconsciously - is in a multicloud scenario.
We distinguish here between multicloud "service procurement" and "service provisioning". In the area of service procurement, we see that SaaS applications are usually obtained from any provider without any problems. In the area of service provision, we assume that applications to generate their own or customer benefits could probably be operated on different cloud platforms, but this is associated with much greater hurdles and higher complexity.
If an application is effectively deployed in a multicloud setup, the goal should be that it can be moved or redirected to other providers at any time based on predefined triggers (availability, cost, location, ...) in a fully automated way. A solid cloud strategy should provide the appropriate framework for this.
In the remainder of this blog, we will go into more depth on the aspects of multicloud service provision of own services and leave the service reference for itself.
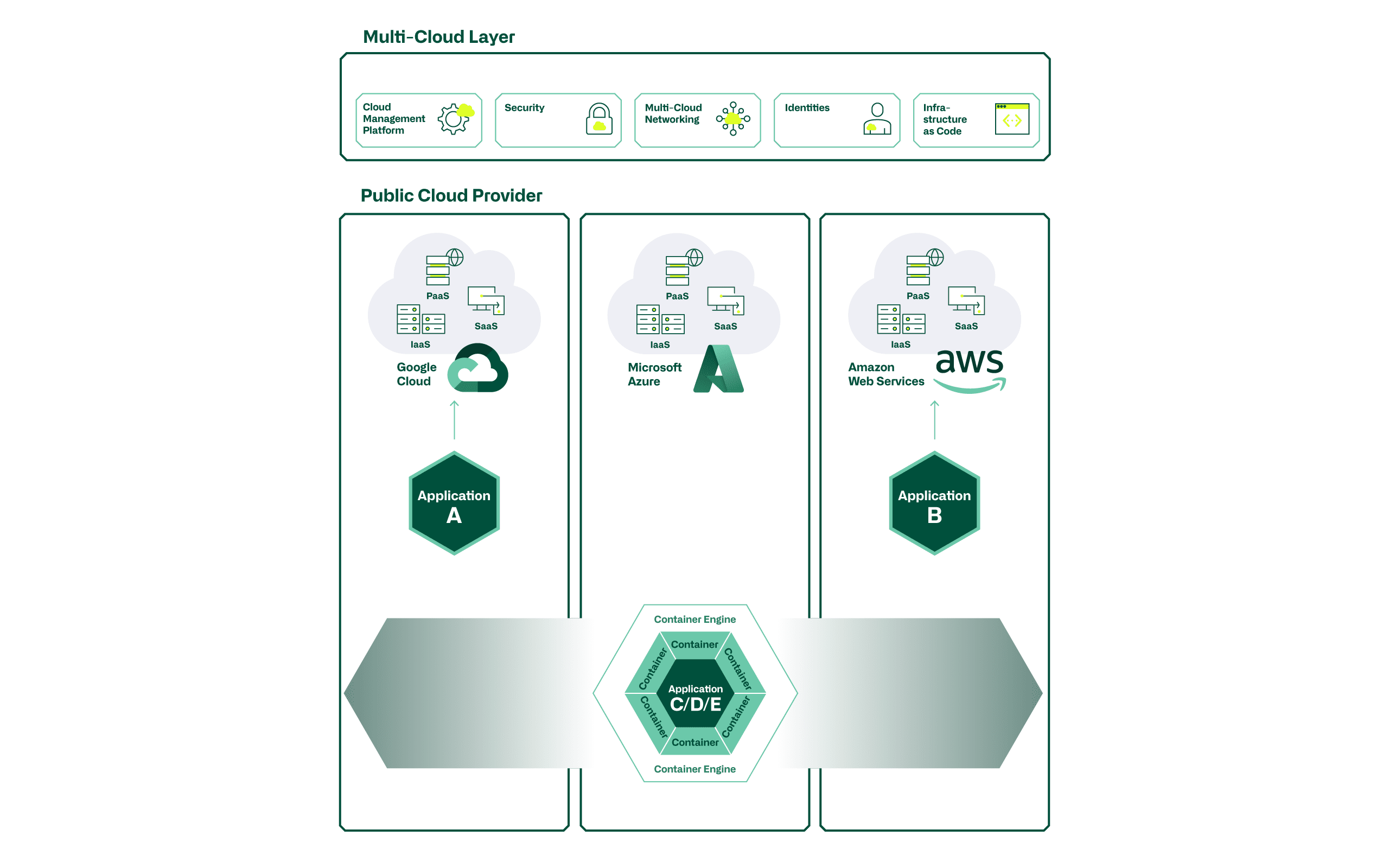
Areas of application for Multicloud
Basically, the question arises as to why a service provision in a multicloud setup should be chosen at all. Due to the fact that each cloud is slightly different from the others, the choice of target platform(s) is driven by the use case to be effectively implemented. Cost aspects are no longer the only factor here. The most important distinguishing features and reasons for operating an application on a specific cloud provider lie in the platform services (serverless functions, BigData, database, machine learning, IoT or AI services).
- For example, there may be reasons to build a BigData Analytics UseCase on AWS, or an IoT UseCase on Azure, because specific strengths, or an optimal integration of a cloud provider want to be used.
If a specific service of a provider is integrated in the application development, e.g. a serverless database from AWS (Amazon Aurora), a counterpart (e.g. Azure SQL Managed Instance) is probably available from another provider, but cannot be accessed via the same API calls. Significant adjustments must therefore be made when porting an application to another provider. The platform services are therefore also a limiting element in the implementation of a multicloud architecture.
In order to be able to operate an application effectively in a provider-independent multicloud setup (horizontally moveable from provider to provider), it must be developed independently of the infrastructure.
- An exemplary use case for this is, for example, a stateless web frontend for web presences used by customers. This can be achieved with container technologies such as Docker and Kubernetes.
Advantages and disadvantages
With the implementation of multcloud scenarios, there are advantages and, of course, also disadvantages. We would like to list a few of them here as examples:
Pros
- Best of breed - effectively using the strengths of the providers
- Avoid vendor lock-in - less dependence on a single provider
- Global-Reach - expansion of the availability zones and simultaneous reduction of the latencies
- High Availability Design - building redundancies across multiple providers
- Compliance - achieving internal & external requirements
Cons
- Traffic costs - transfer from one provider to another causes costs (egress traffic)
- Loss of integration advantages - restrictions in the platform services of the providers (PaaS)
- Increasing complexity on several levels (architecture, service management, provider management, ...)
- Skillset of staff must be available on all providers, which causes high costs
- Reduced economies of scale (e.g. for billing models) compared to a single provider
Supposed advantages are offset by significant disadvantages. Each organisation must analyse and assess the relevant topics for itself. A possible multi-cloud scenario must be developed evolutionarily and the framework conditions must be managed to perfection. Only in this way can the envisaged added values actually be achieved. We will go into more detail in the next section.
Framework conditions
In the next sections, we will address the most important framework conditions. In principle, they also apply in a singlecloud approach, but must be managed with operational excellence in the multicloud scenario.
"Infrastructure as Code(IaC) and thus the fully code-based configuration of all resources is a key element of all cloud projects. This is the only way to ensure quality in recurring activities and to provide and dismantle infrastructures in a fully automated way. For digitalisation, automation is therefore a key element in order to be able to provide resources quickly and with high quality on the basis of customer needs on the respective platforms.
In order to ensure the provision of services across several providers, it is necessary to operate a high-performance and secure "multicloud network". Seamless communication between all services and resources used must be enabled and controlled accordingly across all providers involved.
The resulting potential gateways for hackers or malware must be analysed and reduced as best as possible by means of appropriatesecurity solutions.
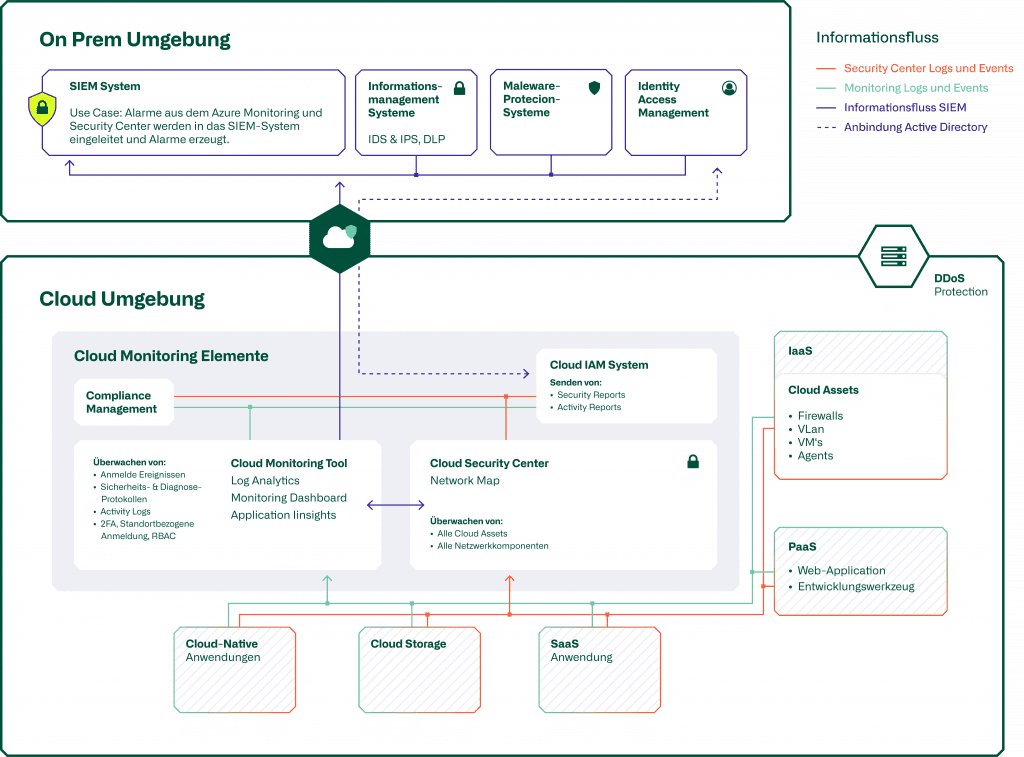
Blog
Cloud Security Monitoring
Supplementary information on this topic can be found in our dedicated blog post.
Cloud management platforms(CMPs) can be used to monitor and control cloud environments (infrastructures & services). They provide an overview and control of orchestration, security, monitoring, costs incurred and optimisation options, so that the full potential can be used and the infrastructures can be operated efficiently.
In the multicloud scenario, a powerful and highly qualified team with the appropriate "know-how/skillset" across all providers and the technologies used is more essential than ever. The complexity with multiple providers increases significantly and the constantly changing services must be managed proactively and with high quality.
We see "standardisation" as the last and sometimes most important framework condition. Since in a multicloud setup an application must not only run on one provider platform, but also on all other potential platforms, all service components must be standardised and abstracted in such a way that they can be operated everywhere. In other words, specific PaaS services of individual providers cannot be used, otherwise portability is not ensured. One solution to this is certainly that the applications are container-based, so that the direct dependence on underlying infrastructure services is reduced as much as possible. Solutions can also be implemented to ensure connectivity and infrastructure interoperability across cloud providers.
Here is an exemplary excerpt of providers/solutions for multicloud projects:
| Kubernetes | Open source system for automating the deployment, scaling and management of containerised applications. |
| HashiCorp | Multicloud automation solutions for infrastructure, security, network and applications. |
| VMware | Multicloud virtualisation layer comparable to OnPremise Software Defined Datacenter solutions. |
| Aviatrix | Multicloud Network and Network Security Automation Solutions |
Blog
Success factors for multi-provider sourcing
In addition to all the technical aspects of multicloud, it is also extremely important to have the contractual management of all the providers involved under control.
Our assessment
As atrete Cloud Consultants, we see that in the medium term most SMEs should focus on a single cloud provider for service delivery. Operational excellence in the essential disciplines can be achieved most quickly in this way. Here, we see the most essential elements as consistently focusing on maximum availability, scaling infrastructures and full automation (infrastructure as code) of all resources. Once the "homework" has been done and there is an effective need / use case for a multicloud implementation, the appropriate framework conditions must be created.
We assume that at most it makes sense for a company's customer-facing core processes to be operated in a multicloud setup. The resulting restrictions in service provision via several cloud providers outweigh this in most other cases. Accordingly, it makes more sense to remain within the ecosystem of a provider for all applications that do not explicitly require multicloud provisioning and to exploit the full potential of the available services (PaaS & SaaS). This makes it possible to operate the cloud infrastructures cost-efficiently.